

This post summarizes some thoughts and experiments on “filtering aware image filtering” I’ve been doing for a while.
The core idea is simple – if you have some “fixed” step at the end of the pipeline that you cannot control (for any reason – from performance to something as simple as someone else “owning” it), you can compensate for its shortcomings with a preprocessing step that you control/own.
I will focus here on the upsampling -> if we know the final display medium, or an upsampling function used for your image or texture, you can optimize your downsampling or pre-filtering step to compensate for some of the shortcomings of the upsampling function.
Namely – if we know that the image will be upsampled 2x with a simple bilinear filter, can we optimize the earlier, downsampling operation to provide a better reconstruction?
Related ideas
What I’m proposing is nothing new – others have touched upon those before.
In the image processing domain, I’d recommend two reads. One is “generalized sampling”, a massive framework by Nehab and Hoppe. It’s very impressive set of ideas, but a difficult read (at least for me) and an idea that hasn’t been popularized more, but probably should.
The second one is a blog post by Christian Schüler, introducing compensation for the screen display (and “reconstruction filter”). Christian mentioned this on twitter and I was surprised I have never heard of it (while it makes lots of sense!).
There were also some other graphics folks exploring related ideas of pre-computing/pre-filtering for approximation (or solution to) a more complicated problem using just bilinear sampler. Mirko Salm has demonstrated in a shadertoy a single sample bicubic interpolation, while Giliam de Carpentier invented/discovered a smart scheme for fast Catmul-Rom interpolation.
As usual with anything that touches upon signal processing, there are many more audio related practices (not surprisingly – telecommunication and sending audio signals were solved by clever engineering and mathematical frameworks for many more decades than image processing and digital display that arguably started to crystalize only in the 1980s!). I’m not an expert on those, but have recently read about Dolby A/Dolby B and thought it was very clever (and surprisingly sophisticated!) technology related to strong pre-processing of signals stored on tape for much better quality. Similarly, there’s a concept of emphasis / de-emphasis EQ, used for example for vinyl records that struggle with encoding high magnitude low frequencies.
Edit: Twitter is the best reviewing venue, as I learned about two related publications. One is a research paper from Josiah Manson and Scott Schaefer looking at the same problem, but specifically for mip-mapping and using (expensive) direct least squares solves, and the other one is a post from Charles Bloom wondering about “inverting box sampling”.
Problem with upsampling and downsampling filters
I have written before about image upsampling and downsampling, as well as bilinear filtering.
I recommend those reads as a refresher or a prerequisite, but I’ll do a blazing fast recap. If something seems unclear or rushed, please check my past post on up/downsampling.
I’m going to assume here that we’re using “even” filters – standard convention for most GPU operations.
Downsampling – recap
A “Perfect” downsampling filter according to signal processing would remove all frequencies above the new (downsampled) Nyquist before decimating the signal, while keeping all the frequencies below it unchanged. This is necessary to avoid aliasing.
Its frequency response would look something like this:

If we fail to anti-alias before decimating, we end up with false frequencies and visual artifacts in the downsampled image. In practice, we cannot obtain a perfect downsampling filter – and arguably would not want to. A “perfect” filter from the signal processing perspective has an infinite spatial support, causes ringing, overshooting, and cannot be practically implemented. Instead of it, we typically weigh some of the trade-offs like aliasing, sharpness, ringing and pick a compromise filter based on those. Good choices are some variants of bicubic (efficient to implement, flexible parameters) or Lanczos (windowed sinc) filters. I cannot praise highly enough seminal paper by Mitchell and Netravali about those trade-offs in image resampling.
Usually when talking about image downsampling in computer graphics, the often selected filter is bilinear / box filter (why are those the same for the 2x downsampling with even filters case? see my previous blog post). It is pretty bad in terms of all the metrics, see the frequency response:
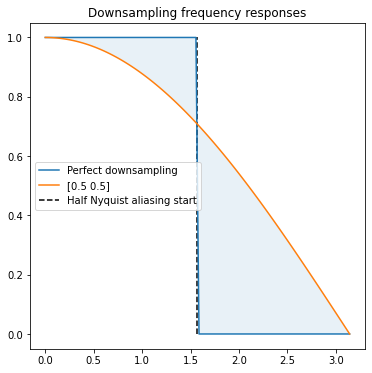
It has both aliasing (area to the right of half Nyquist), as well as significant blurring (area between the orange and blue lines to the left of half Nyquist).
Upsampling – recap
Interestingly, a perfect “linear” upsampling filter has exactly the same properties!
Upsampling can be seen as zero insertion between replicated samples, followed by some filtering. Zero-insertion squeezes the frequency content, and “duplicates” it due to aliasing.
When we filter it, we want to remove all the new, unnecessary frequencies – ones that were not present in the source. Note that the nearest neighbor filter is the same as zero-insertion followed by filtering with a [1, 1] convolution (check for yourself – this is very important!).
Nearest neighbor filter is pretty bad and leaves lots of frequencies unchanged.
A classic GPU bilinear upsampling filter is the same as a filter: [0.125, 0.375, 0.375, 0.125] and it removes some of the aliasing, but also is strong over blurring filter:
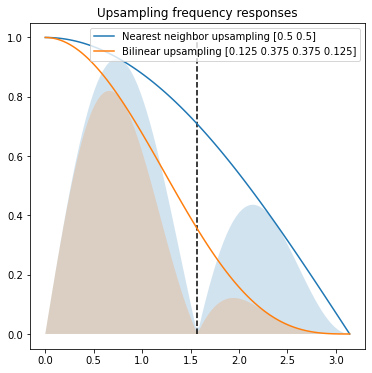
We could go into how to design a better upsampler, go back to the classic literature, and even explore non-linear, adaptive upsampling.
But instead we’re going to assume we have to deal and live with this rather poor filter. Can we do something about its properties?
Downsampling followed by upsampling
Before I describe the proposed method, let’s have a look at what happens when we apply a poor downsampling filter and follow it by a poor upsampling filter. We will get even more overblurring, while still getting remaining aliasing:
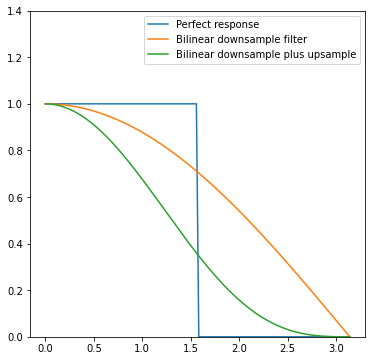
This is not just a theoretical problem. The blurring and loss of frequencies on the left of the plot is brutal!
You can verify it easily looking at a picture as compared to downsampled, and then upsampled version of it:

In motion it gets even worse (some aliasing and “wobbling”):

Compensating for the upsampling filter – direct optimization
Before investigating some more sophisticated filters, let’s start with a simple experiment.
Let’s say we want to store an image at half resolution, but would like it to be as close as possible to the original after upsampling with a bilinear filter.
We can simply directly solve for the best low resolution image:
Unknown – low resolution pixels. Operation – upsampling. Target – original full resolution pixels. The goal – to have them be as close as possible to each other.
We can solve this directly, as it’s just a linear least squares. Instead I will run an optimization (mostly because of how easy it is to do in Jax! 🙂 ). I have described how one can optimize a filter – optimizing separable filters for desirable shape / properties – and we’re going to use the same technique.
This is obviously super slow (and optimization is done per image!), but has an advantage of being data dependent. We don’t need to worry about aliasing – depending on presence or lack of some frequencies in an area, we might not need to preserve them at all, or not care for the aliasing – and the solution will take this into account. Conversely, some others might be dominating in some areas and more important for preservation. How does that work visually?

This looks significantly better and closer – not surprising, bilinear downsampling is pretty bad. But what’s kind of surprising is that with Lanczos3, it is very similar by comparison:

It’s less aliased, but the results are very close to using bilinear downsampling (albeit with less aliased edges), that might be surprising, but consider how poor and soft is the bilinear upsampling filter – it just blurs out most of the frequencies.
Optimizing (or directly solving) for the upsampling filter is definitely much better. But it’s not a very practical option. Can we compensate for the upsampling filter flaws with pre-filtering?
Compensating for the upsampling filter with pre-filtering of the lower resolution image
We can try to find a filter that simply “inverts” the upsampling filter frequency response. We would like a combination of those two to become a perfect lowpass filter. Note that in this approach, in general we don’t know anything about how the image was generated, or in our case – the downsampling function. We are just designing a “generic” prefilter to compensate for the effects of upsampling. I went with Lanczos4 for the used examples to get to a very high quality – but I’m not using this knowledge.
We will look for an odd (not phase shifting) filter that concatenated with its mirror and multiplied by the frequency response of the bilinear upsampling produces a response close to an ideal lowpass filter.
We start with an “identity” upsampler with flat frequency response. It combined with the bilinear upsampler, yields the same frequency response:

However, if we run optimization, we get a filter with a response:
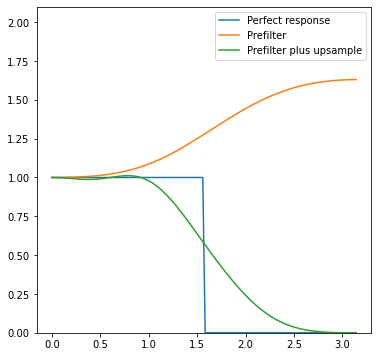
The filter coefficients are…
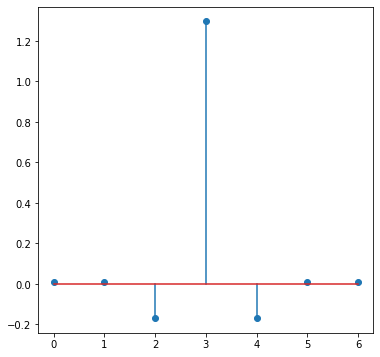
Yes, that’s a super simple unsharp mask! You can safely ignore the extra samples and go with a [-0.175, 1.35, -0.175] filter.
I was very surprised by this result at first. But then I realized it’s not as surprising – as it compensates for the bilinear tent-like weights.
Something rings a bell… sharpening mip-maps… Does it sound familiar? I will come back to this in one of the later sections!
When we evaluate it on the test image, we get:

However if we compare against our “optimized” image, we can see a pretty large contrast and sharpness difference:

The main reason for this (apart from local adaptation and being aliasing aware) is that we don’t know anything about downsampling function and the original frequency content.
But we can design them jointly.
Compensating for the upsampling filter – downsample
We can optimize for the frequency response of the whole system – optimize the downsampling filter for the subsequent bilinear upsampling.
This is a bit more involved here, as we have to model steps of:
- Compute response of the lowpass filter we want to model <- this is the step where we insert variables to optimize. The variables are filter coefficients.
- Aliasing of this frequency response due to decimation.
- Replication of the spectrum during the zero-insertion.
- Applying a fixed, upsampling filter of [0.125, 0.375, 0.375, 0.125].
- Computing loss against a perfect frequency response.
I will not describe all the details of steps 2 and 3 here -> I’ll probably write some more about it in the future. It’s called multirate signal processing.
Step 4. is relatively simple – a multiplication of the frequency response.
For step 5., our “perfect” target frequency response would be similar to a perfect response of an upsampling filter – but note that here we also include the effects of downsampling and its aliasing. We also add a loss term to prevent aliasing (try to zero out frequencies above half Nyquist).
For step 1, I decided on an 8 tap, symmetric filter. This gives us effectively just 3 degrees of freedom – as the filter has to normalize to 1.0. Basically, it becomes a form of [a, b, c, 0.5-(a+b+c), 0.5-(a+b+c), c, b, a]. Computing frequency response of symmetric discrete time filters is pretty easy and also signal processing 101, I’ll probably post some colab later.
As typically with optimization, the choice of initialization is crucial. I picked our “poor” bilinear filter, looking for a way to optimize it.
Without further ado, this is the combined frequency response before:
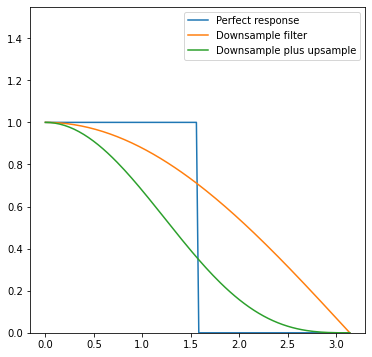
And this is it after:
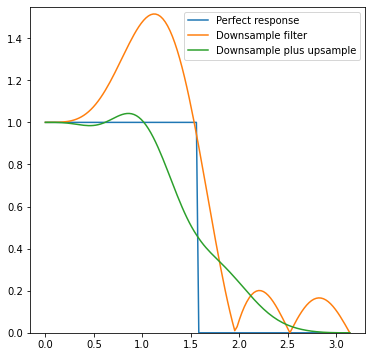
The green curve looks pretty good! There is small ripple, and some highest frequency loss, but this is expected. There is also some aliasing left, but it’s actually better than with the bilinear filter.
Let’s compare the effect on the upsampled image:

I looked so far at the “combined” response, but it’s insightful to look again, but focusing on just the downsampling filter:
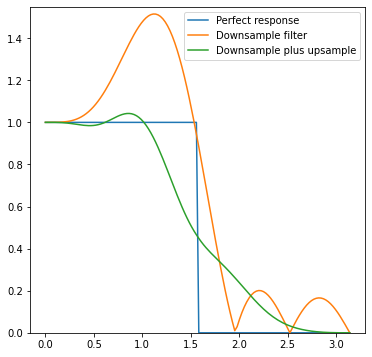
Notice relatively strong mid-high frequency boost (this bump above 1.0) – this is to “undo” the subsequent too strong lowpass filtering of the upsampling filter. It’s kind of similar to sharpening before!
At the same time, if we compare it to the sharpening solution:

We can observe more sharpness and contrast preserved (also some more “ringing”, but it was also present in the original image, so doesn’t bother me as much).
Different coefficient count
We can optimize for different filter sizes. Does this matter in practice? Yes, up to some extent:

I can see the difference up to 10 taps (which is relatively a lot). But I think the quality is pretty good with 6 or 8 taps, 10 if I there is some more computational budget (more on this later).
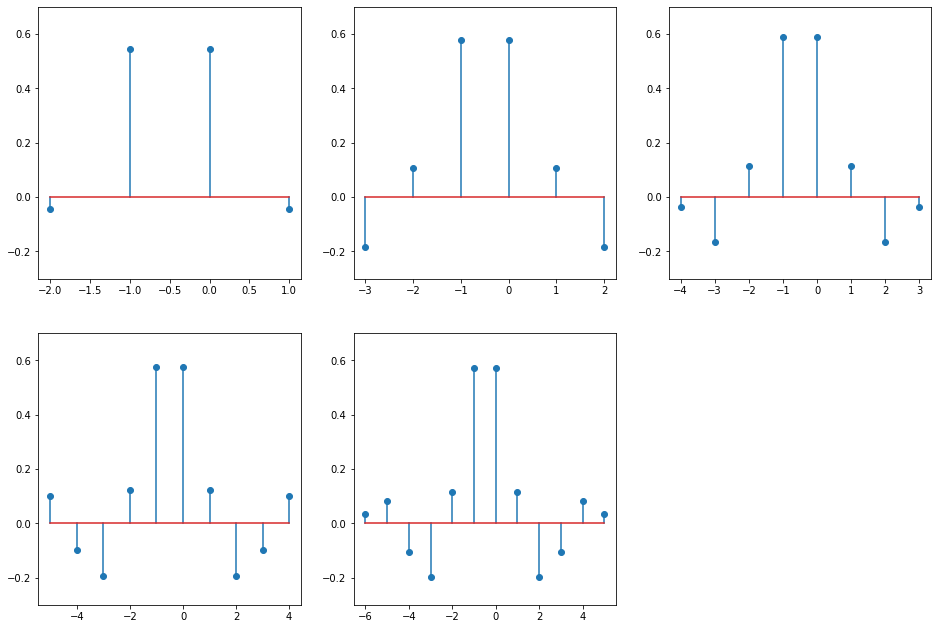
If you’re curious, this is how coefficients look like on plots:
Efficient implementation
You might wonder about the efficiency of the implementation. 1D filter of 10 taps means… 100 taps in 2D! Luckily, proposed filters are completely separable. This means you can downsample in 1D, and then in 2D. But 10 samples is still a lot.
Luckily, we can use an old bilinear sampling trick.
When we have two adjacent samples of the same sign, we can combine them together and in the above plots, turn the first filter into a 3-tap one, the second one into 4 taps, third one into an impressive 4, then 6, and also 6.
I’ll describe quickly how it works.
If we have two samples with offsets -1 and -2 and the same weights of 1.0, we can instead take a single bilinear tap in between those – offset of -1.5, and weight of 2.0. Bilinear weighting distributes this evenly between sample contributions.
When the weights are uneven, it still is w_a + w_b total weight, but the offset between those is w_a / (w_a + w_b).
Here are the optimized filters:
[(-2, -0.044), (-0.5, 1.088), (1, -0.044)]
[(-3, -0.185), (-1.846, 0.685), (0.846, 0.685), (2, -0.185)]
[(-3.824, -0.202), (-1.837, 0.702), (0.837, 0.702), (2.824, -0.202)]
[(-5, 0.099), (-3.663, -0.293), (-1.826, 0.694), (0.826, 0.694), (2.663, -0.293), (4, 0.099)]
[(-5.698, 0.115), (-3.652, -0.304), (-1.831, 0.689), (0.83, 0.689), (2.651, -0.304), (4.698, 0.115)]
I think this makes this technique practical – especially with separable filtering.
Sharpen on mip maps?
One thing that occurred to me during those experiments was the relationship between a downsampling filter that performs some strong sharpening, sharpening of the downsampled images, and some discussion that I’ve had and seen many times.
This is not just close, but identical to… a common practice suggested by video game artists at some studios I worked at – if they had an option of manually editing mip-maps, sometimes artists would manually sharpen mip maps in Photoshop. Similarly, they would request such an option to be applied directly in the engine.
Being a junior and excited programmer, I would eagerly accept any feature request like this. 🙂 Later when I got grumpy, I thought it’s completely wrong – messing with trilinear interpolation, as well as being wrong from signal processing perspective.
Turns out, like with many many practices – artists have a great intuition and this solution kind of makes sense.

I would still discourage it and prefer the downsampling solution I proposed in this post. Why? Commonly used box filter is a poor downsampling filter. Applying sharpening onto it enhances any kind of aliasing (as more frequencies will tend to alias as higher ones), so can have a bad effect on some content. Still, I find it fascinating and will keep repeating that artists’ intuition about something being “wrong” is typically right! (Even if some proposed solutions are “hacks” or not perfect – they are typically in the right direction).
Summary
I described a few potential approaches to address having your content processed by “bad” upsampling filtering, like a common bilinear filter: an (expensive) solution inverting the upsampling operation on the pixels (if you know the “ground truth”), simple sharpening of low resolution images, or a “smarter” downsampling filter that can compensate for the effect that worse upsampling might have on content.
I think it’s suitable for mip-maps, offline content generation, but also… image pyramids. This might be topic for another post though.
You might wonder if it wouldn’t be better to just improve the upsampling filter if you can have control over it? I’d say that changing the downsampler is typically faster / more optimal than changing the upsampler. Less pixels need to be computed, it can be done offline, upsampling can use the hardware bilinear sampler directly, and in the case of complicated, multi-stage pipelines, data dependencies can be reduced.
I have a feeling I’ll come back to the topics of downsampling and upsampling. 🙂

I always enjoy reading about your signal-processing approach for analyzing images.
Thank you for sharing this.
I have 2 questions:
1. The suggested approach indeed yields a better (less blurry) image. I was wondering how does it look under camera motion? Does the “wobbling” you showed in the animation for bilinear upsampling (without pre-filtering) get worse when optimal pre-filtering applied?
2. I was wondering how the optimal pre-filter would look like if you were optimizing for a better upsampling algo (let’s say a generic bicubic spline). I’d love to get your opinion. My intuition says that you’ll still want to sharpen, but you may get away with fewer taps.
Thanks! Great questions, and both are actually and surprisingly related 🙂
1. It should perform relatively comparable to a bilinear filter. The reason is similar amount of aliasing during downsampling. Amount of frequencies above half Nyquist that are let through is a bit smaller, but on the other hand, some of the boosted frequencies will alias on upsampling. I can try to add a comparison.
2. For the first part (less sharpening) yes, but not necessarily less taps. Amount of filter taps is related to the downsampling getting closer and closer to an ideal low pass filter (sinc). It’s impossible (nor desireable) to have a perfect one, but it would use infinitely many samples. Sharpening gets reasonable frequency response actually pretty quickly, it’s the anti-aliasing part that requires many samples…
I was very confused when you said a bilinear upsample has coefficients [1/8, 3/8, 3/8, 1/8]. For one thing, it doesn’t have DC gain when combined with zero insertion, so the equivalent two-tap filter is not [1, 1] but [1/2, 1/2]. I read your previous post where you motivate your choice, but this still seems inadequate, especially if you are talking frequency responses and sharpness.
The simpler choice is the triangular kernel [1/4, 1/2, 1/4] which doesn’t have the half sample offset. Given that [1/4, 1/2, 1/4] ⊗ [1/2, 1/2] = [1/8, 3/8, 3/8, 1/8] this also highlights that the GPU-aligned version of the linear upsample is _blurrier_ than a normal linear interpolation, and requires more compensation.
That is to say, while there are certainly situations where centered samples are preferable over corner samples, it seems ridiculous to say that “Tensorflow got it wrong” in a post where you are trying to undo the blur your yourself added in on purpose.
I mean, this is how GPUs work. This is how their filter looks like – and not my choice. Check it for yourself by upsampling a single line… ¯\_(ツ)_/¯
Pingback: Exposure Fusion – local tonemapping for real-time rendering | Bart Wronski
Pingback: Fast, GPU friendly, antialiasing downsampling filter | Bart Wronski
You should have listed your coefficients used in the “Different coefficient count” before proposing how to optimize them in “Efficient implementation” to make reproduction easier for cases that don’t have means of hardware interpolation (for example, implementing this on the CPU).
I have implemented both of your 6-tap filters as well as the sharpening “postprocess” filter to downscale mip chains. For each of these filters, I apply them recursively to downscale an image 32x, then linearly upscale it back to the original resolution.
What I’m seeing is that the sharpening filter seems to work pretty well and actually makes mips look noticeably better, I’m quite impressed.
However, your proposed optimized filters seem to produce a results that closely resembles the box filter after recurrent applications.
I suspect it’s either because you optimized your filter specifically for the image that you ran it on, or you didn’t optimize it for multiple recurrent applications (for downscaling greater than 2x).
Hey, if I understand you correctly, then this is +/- expected.
1. As you note, this filter is optimized exclusively for a single upsampling operation, but more importantly…
2. The filter is not optimized for a single image, but a “least-squares” global fit that attempts to suppress aliasing and sharpen at the same time. Those two are at odds. An image-optimized or even locally-optimized image (approach which I describe earlier in the post) would be much better as it wouldn’t need to compromise those for “any image” with “any content”. I could also try to take general image spectral decay weighting into account during the optimization to improve this on average on natural images, but also don’t expect miracles because…
3. The final filter – bilinear with a massive upsampling ratio – will dominate the look. You can try optimizing for different bilinear upsampling ratios.
4. Finally, I would not expect miracles in general. 🙂 If you upsample 16x with bilinear, so much information is gone during decimation and the filter is so poor, that it cannot look great.
While I agree with every point here, fact is a fact: your simplest post-process sharpening filter [-0.175, 1.35, -0.175] does produce a sharper image without introducing too much aliasing when compared to box filter on every image that I tried it on, regardless of magnification, even though I tried up to 64x on every image I tried. However, since it’s a “post-processing” type of filter and only 3 pixels wide, one should expect it to perform worse than wider more advanced filters created to do downscaling at the same time with filtering, but it just does not seem to be the case.
I have even made a demo to compare them: https://www.shadertoy.com/view/dstyDN bottom-up: box filter, sharpening postprocess, 6-bilinear-taps wide filter from this article, the reference. I suggest observing them in the fullscreen. You can clearly see that the simple sharpening filter seems to perform the best.
My question is: why? What’s special about that filter? Since there’s some sort of a criterion by which it performs better, how can one optimize that criterion to produce a filter that does perform the best under recurrent application?
You can always design arbitrarily “sharper” filters that will look “better”, where the definition of better is subjective. The thing about the designed filter in this article is that it simultaneously tries to minimize aliasing, which compromises maximum possible sharpness. This will produce content-dependent results, for instance reduce moire on some extremely high resolution results. Also L2 minimization is known to produce results that are blurrier subjectively, as it optimizes for average of every possible solution. This is a great paper about it that was quite transformative in image processing and machine learning https://arxiv.org/abs/1711.06077 .
And why would we care about L2/distortion/objective metrics? Because most textures used in computer graphics do not even represent color, but some other physical properties. Would you want sharp normals? Sometimes, as long as it doesn’t cause geometric distortion…
If in graphics some method produces a result that visually looks better, but that performs worse when measured by a metric, it means the metric is flawed. It’s easy to dismiss something by saying “it should not work according to the theory, hence it only looks better because you’re subjectively looking it at”. But you’ve gotta put your money where your mouth is and admit that most of the time when this happens, it means that there’s something happening that’s worth understanding.
If the simple sharpening filter looks better (even if it’s subjective) despite the ringing it introduces, then it means there’s some value to it. And that there is some metric that corresponds to this “looking better”, hence there has to be a way to optimize for it, even for arbitrarily high magnification factors.
Here you are completely wrong, sorry.
1. Please read this paper. When there are many possible answers, an objective metric gives an average of one, which does not align with perception. Giving one of multiple better perceptually answers instead is hallucination.
2. I worked 5y on consumer camera software, and subjective metrics are VERY different. Across individuals, cultures, you name it. For exactly the same photo, some preferred it sharpened, some soft. Some wanted denoised, some not. We tended to compromise and give natural result, which later can be tweaked (like sharpened). There is no metric that will capture it because it’s not a single judgement, but a personalized sample from a distribution of all possible opinions.