

In this post I want to close the loop and come back to the topic I described ~6y ago!
Local tonemapping (I’ll refer to it as LTM) – a component I considered a missing piece in video games rendering, especially with physically-based pipelines and using real/physical sky/sun models.
Global tonemapping is not enough for casual photography (where we don’t control the lighting), and while games can “hack” things, I considered LTM an almost a must have tool that can be used in some cases.
I have described a simple hacked solution that I implemented for God of War, but I was never happy with it – it helped in some scenes, but pushing it caused all kinds of ugly halo artifacts:

Later I remember discussions on twitter about using “bilateral grid” (really influential older work from my ex colleague Jiawen “Kevin” Chen) to prevent some halos, and last year Jasmin Patry gave an amazing presentation about tonemapping, color, and many other topics in “Ghost of Tsushima” that uses a mix of bilateral grid and Gaussian blurs. I’ll get back to it later.
What I didn’t know when I originally wrote my post was that a year later, I would join Google, and work with some of the best image processing scientists and engineers on HDR+ – computational photography pipeline that includes many components, but one of the key signature ones is local tonemapping – the magic behind “HDR+ look” that is praised by both the reviewers and users.
The LTM solution is a fairly advanced pipeline, the result of the labor and love of my colleague Ryan (you might know his early graphics work if you ever used Winamp!) with excellent engineering, ideas, and endless patience for tweaks and tunings – a true “secret sauce”.
But the original inspiration and the core skeleton is a fairly simple algorithm, “Exposure Fusion”, which can both deliver excellent results, as well as be implemented very easily – and I’m going to cover it and discuss its use for real time rendering.
This post comes with a web demo in Javascript and obviously with source code. To be honest it was an excuse for me to learn some Javascript and WebGL (might write some quick “getting started” post about my experience), but I’m happy how it turned out.
So, let’s jump in!
Some disclaimers
In this post I will be using a HDRI by Greg Zaal.
Throughout the post I will be using ACES global tonemapper – I know it has a bad reputation (especially per-channel fits) and you might want to use something different, but its three js implementation is pretty good and has some of the proper desaturation properties. Important to note – in this post I don’t assume anything about the used global tonemapper and its curves or shapes – most will work as long as they reduce dynamic range. So in a way, this technique is orthogonal to the global tonemapping look and treatment of colors and tones.
Finally, I know how many – including myself – hate the “toxic HDR” look that was popular in the early noughties – and while it is possible to achieve it with the described method, it doesn’t have to be – this is a matter of tuning parameters.
Note that if you ever use Lightroom or Adobe Camera Raw to open RAW files in Photoshop, you are using a local tonemapper! Simply their implementation is very good and has subtle, reasonable defaults.
Localized exposure, local tonemapping – recap of the problem
In my old post, I went quite deep into why one might want to use a localized exposure / localized tonemapping solution. I encourage you to read it if you haven’t, but I’ll quickly summarize the problem here as well.
This problem occurs in photography, but we can look at it from a graphics perspective.
We render a scene with a physically correct pipeline, using physical values for lighting, and have an HDR representation of the scene. To display it, you need to adjust exposure and tonemap it.
If your scene has a lot of dynamic range (simplest case – a day scene with harsh sunlight and parts of the scene in shadows), picking the right exposure is challenging.
If we pick a “medium” exposure, exposing for the midtones, we get something “reasonable”:

On the other hand, details in the sunlit areas are washed out and barely visible, and information in the shadows is completely dark and barely visible.
You might want to render a scene like this – high contrast can be a desired outcome with some artistic intent. In some other cases it might not be – and this is especially important in video games that are not just pure art, but visuals need to serve gameplay and interactive purposes – very often, you cannot have important detail not visible.
If we try to reduce the contrast, we can start seeing all the details, but everything looks washed out and ugly:

We want to keep the original, punchy look, but still be able to see all the relevant details. How can we do that?
Let’s get back to selecting the exposure – here are three different exposures:

None of them is perfect when it comes to representing all details in the scene, but each one of them produces a clear, pleasant look in a certain area.
I have marked it with a green circle area “properly exposed” regions – where we can see all the details. Locally, in those regions, those images look perfect for our intent – and we are going to produce a single image that combines all of those.
Alternative solutions
It’s worth mentioning how this problem can be solved in other ways.
My previous post described some solutions used in photography, filmography, and video games. Typically it involves either manually brightening/darkening some areas (famous Ansel Adams dodge/burn aspects of the zone system), but it can start much earlier, before taking the picture – by inserting artificial lights that reduce contrast of the scene, tarps, reflectors, diffusers.
In video games it is way easier to “fake” it, and break all physicality completely – from lights through materials to post fx – and while it’s an useful tool, it reduces the ease and potential of using physical consistency and ability to use references and real life models. Once you hack your sky lighting model, the sun or artificial lights at sunset will not look correctly…
Or you could brighten the character albedos – but then the character art director will be upset that their characters might be visible, but look too chalky and have no proper rim specular. (Yes, this is a real anecdote from my working experience. 🙂 )
In practice you want to do as much as you can for artistic purposes – fill lights and character lights are amazing tools for shaping and conveying the mood of the scene. You don’t want to waste those, their artistic expressive power, and performance budgets to “fight” with the tonemapper…
Blending exposures
So we have three exposures – and we’d want to blend them, deciding per region which exposure to take.
There are a few ways to go about it, let’s go through them and some of their problems.
Per-pixel blending
The simplest option is very simple indeed – just deciding per pixel how to blend the three exposures depending on how well exposed they are.
This doesn’t work very well:

Ok, I take it even further – this is super ugly!
Everything looks washed out and weirdly saturated. It resembles a lot of the “toxic HDR” look mixed with washed out low contrast.
The problem is that even a dark region might have some bright pixels – and if we bring them down instead of up, it reduces the contrast.
Gaussian blending
The second alternative is simple – blurring the pixel luminance (a lot!) before deciding on how to adjust the local exposure / which exposure to use.
This is the approach I have described in my previous post and what we used for the God of War. And it can work “ok”, but generates pretty bad halos:

Bright regions trying to bring the dark ones down will leak onto medium exposure and dark regions, darkening them further and vice versa – dark regions strong influence will leak onto the surroundings. On a still image it can look acceptable, but with a video game moving camera it is visible and distracting…
Bilateral blending
Given that we would like to prevent bleeding over edges, one might try to use some form of edge-preserving or edge-stopping filter like bilateral. And it’s not a bad idea, but comes with some problems – gradient reversals and edge ringing.
I will refer you here to the mentioned excellent Siggraph presentation by Jasmin Patry who has analyzed where those come from.
In his Desmos calculator he demos the problem on a simple 1D edge:
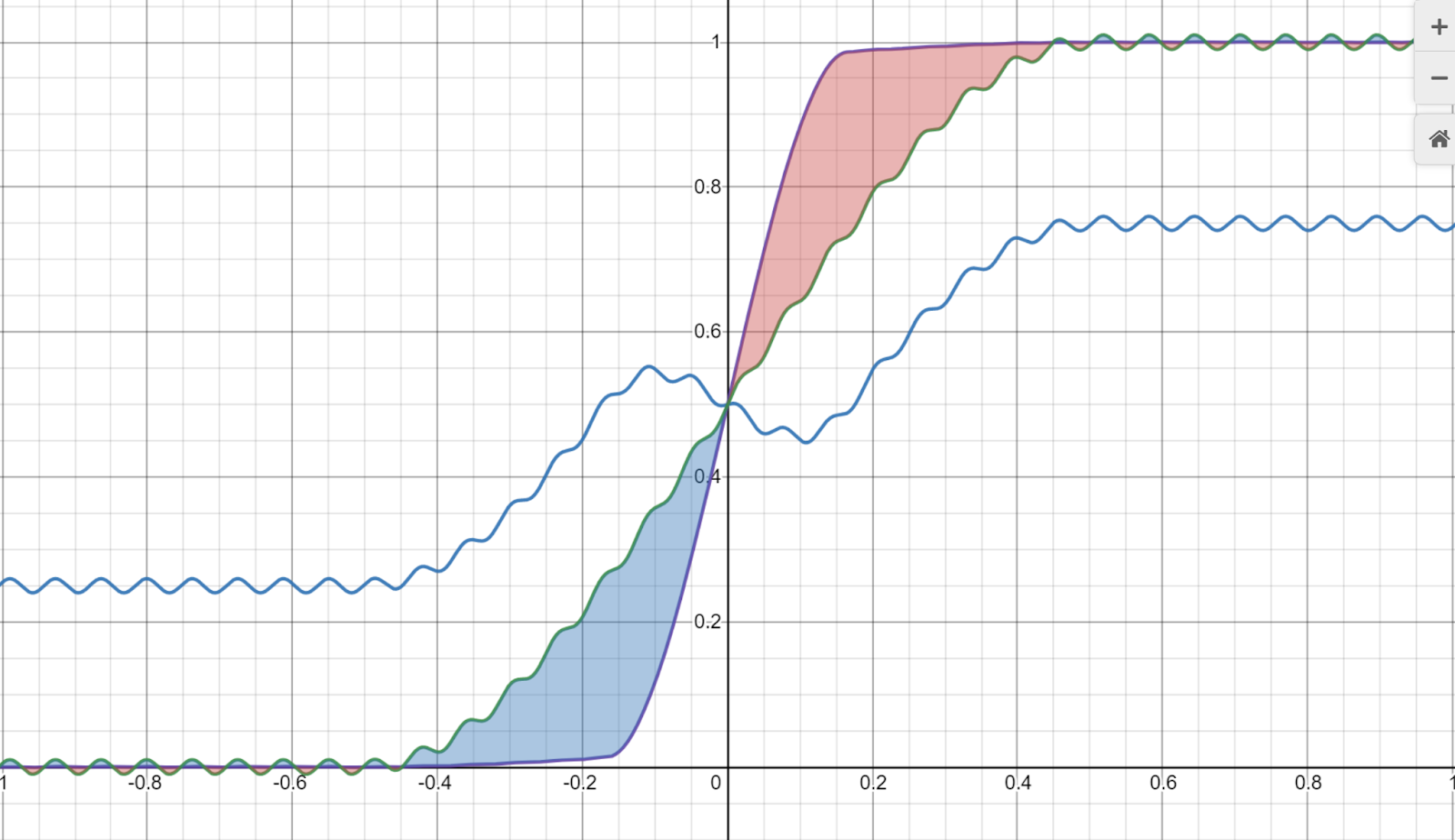
His proposed solution to this problem (to blend bilateral with Gaussian) is great and offers a balance between halos and edge/gradient reversals and ringing that can occur with bilateral filters.
But we can do even better and reduce the problem further through Exposure Fusion. But before we do, let’s look first however at a reasonable (but also flawed) alternative.
Guided filter blending
A while ago, I wrote about the guided filter – how local linear models can be very useful and in some cases can work much better (and more efficiently!) than a joint bilateral filter.
I’ll refer you to the post – and we will be actually using it later for speeding up the processing, so might be worth refreshing.
If we try to use a guided filter to transfer exposure information from low resolution / blurry image with blended exposure to full resolution, we end up with a result like this:

It’s actually not too bad, but notice that it tends to blur out some edges and reduce the local contrast as compared to the exposure fusion technique we’re going to have a look at next:

Exposure fusion
“Exposure fusion” by Mertens et al attempts to solve blending multiple globally tonemapped exposures (can be “synthetic” in the case of rendering), but in a way that preserves detail, edges, and minimizes halos.
It starts with an observation that depending on the region of the image and presence of details, sometimes you want to have a wide blending radius, sometimes very sharp.
Anytime you have a sharp edge – you want your blending to happen over a small area to avoid a halo. Anytime you have a relatively flat region – you want blending to happen over a large area, smoothen and be imperceptible.
The way authors propose to achieve it is through blending different frequency information with a different radius.
This might be somewhat surprising and it’s hard to visualize, but let me attempt it. Here we change the exposure rapidly over a small horizontal line section:

Notice how the change is not perceivable on the top of the image, this could be a normal picture, while on the bottom it is very harsh. Why? Because on top, the high frequency change correlates with high frequency information and image content change, while on the bottom it is applied to the low frequency information.
The key insight here is that you want frequency of the change to correlate with the frequency content of the image.
On low frequency, flat regions, we are going to use a very wide blending radius. In areas with edges and textures, we are going to make it steeper and stop around them. Changes in brightness are hidden by the edges or alternatively, smoothened out over large edgeless regions!
Authors propose a simple approach: Construct Laplacian pyramids for each blended image – and blend those Laplacians. Laplacian blending radius is proportional to the Laplacian radius – and can be trivially constructed by creating a Gaussian pyramid of the weights.
Here is a figure from the paper that shows how simple (and brilliant) the idea is:

I will describe later some GPU implementation details and parameters used how to make it behave well, but first let’s have a look at the results:

This looks really good! Contrasty, punchy look, details visible everywhere. Compared to the global tonemapping (apologies for GIF banding artifacts):

What I like about this picture is the lack of halos, lack of washout effect, proper local contrast, proper details, overall relatively subtle look. This might not be the look you’d want for that scene – obviously this is an artistic process – but it looks correct.
Algorithm details
I highly encourage you to read the paper, but here is a short description of all of the steps:
- Create “synthetic exposures” by tonemapping your image with different exposure settings. In general the more – the better, but 3 are a pretty good starting choice, allowing for separate control of “shadows” and highlights.
- Compute the “lightness” / “brightness” image from each synthetic exposure. Gamma-mapped luminance is an extremely crude and wrong approximation, but this is what I used in the demo to simplify it a lot.
- Create a Laplacian pyramid of each lightness image up to some level – more about it later. This last level will be just Gaussian-blurred, low resolution version of the given exposure, all the other will be Laplacian – difference between two Gaussian levels.
- Assign a per-pixel weight to each high resolution lightness image. Authors propose to use three metrics – contrast, saturation, and exposure – closeness to gray. In practice if you want to avoid some of the over-saturated, over-contrasty look, I recommend using just the exposure.
- Create a Gaussian pyramid of the weights.
- On some selected coarse level (like on the 5th or 6th mip-map), blend the coarsest Gaussian lightness mip-maps with the Gaussian weights.
- Go towards the finer pyramid levels / resolution – and on each level, blend Laplacians using a given level Gaussian and add it to the accumulated result.
- Transfer the lightness to the full target image and do the rest of your tonemapping and color grading shenanigans.
Voila! We have an image in which edges (Laplacians) are blended at different scales with different radii.
In practice, getting this algorithm to look very well in multiple conditions (it has some unintuitive behaviors) requires some tricks and some tuning – but in a nutshell it’s very simple!
Optional – local contrast boost
One interesting option that the algorithm gives us is to boost the local contrast. It can be done in a few ways, but one that is pretty subtle and I like is to include the Laplacian magnitudes when deciding on the blending weights. Our effective weight will be Gaussian of the per-pixel weights times the absolute value of the magnitude. Note that generally this again is done per scale – so each scale weight is picked separately.
Produced local contrast boost can be visually pleasing:

It actually reduces some of the “flat” look that every LTM operator can produce when pushed to the extreme.
If you are a Lightroom user, their “Clarity” slider has a very similar effect and while the algorithm is proprietary (most likely a variant of “Local Laplacian Filter”), the general mechanism of action is very similar as well!
Extreme settings
I will describe algorithm / implementation parameters in the next section, but I couldn’t resist producing some “extreme toxic HDR” look as well – mostly to show that the algorithm is capable of doing so (if this is your aesthetic preference – and for some cases like architecture visualization it seems to be…).

Not my look and definitely in artificial territories, but still, not too bad – there are some dark halos here and there, weird washouts, but the algorithm seems to perform reasonably well.
Parametrization
Here are some of the algorithm parameters and the way I parametrized it.
Exposure
This one is the most straightforward. Exposure describes preferred overall average and “midtone” scene brightness.
Here are three exposure levels (for comparison – top row is with LTM off and the bottom is on):

Shadows and highlights
Shadows and highlights in my proposed parametrization describe how much to darken or brighten the synthetic exposures as compared to the global/middle exposure value.
Here is the same image with the same exposure with left having the highest value of “shadows” (biggest exposure boost of the brightest image), center with both of them at 0, and the right with maximum “highlights”:

Those are extreme and not recommended values – but the concept of tuning separately shadows and highlights is very important for artistic control over the tonemapping. It is part of the image and the look, and should be decided with artistic intent and for the scene mood.
Coarsest mip level
The final two important parameters are the most counter-intuitive.
When we decide up to which level we’d want to construct the pyramids, we decide which frequencies will be blended together (anything at that mip level and above). Setting the mip level to 0 is equivalent to full per-pixel weights and blending. On the other hand, setting it to maximum blends each level as Laplacian.
The lower the coarsest level, the more dynamic range compression there is – but also more washed out, fake-HDR look.
Here are mip levels 0, 5, 9:

Thing to notice is the increasing amount of local contrast (see for example the floor, especially close to table leg). The leftmost picture lacks some local contrast and gets washed out, but has the most dynamic range compression.
This might not be very clear, so I recommend you play with it in the demo to build some intuition.
Exposure preference sigma
This is the final parameter – it describes how “strong” the weighting preference is based on closeness of the lightness to 0.5. It affects the overall strength of the effect – with zero providing almost no LTM (all exposure weights are the same!), and with extreme settings producing artifacts and overcompressed look (pixels getting contribution only from a single exposure with some discontinuities):

(Notice the artifacts on the rightmost image on the table and when highlights blend with the midtones)
I again recommend you play with it yourself to build some intuition.
Algorithm problems
Overall, I like the algorithm a lot and find it excellent and able to produce great results.
The biggest problem is its counterintuitive behavior that depends on the image frequency content. Images with strong edges will compress differently, with a different look than images with weak edges. Even the frequency of detail (like fine scale – foliage vs medium scale like textures) matters and will affect the look. This is a problem as a certain value of “shadows” will brighten actual shadows of scenes differently depending on their contents. This is where artist control and tuning come into play. While there are many sweet spots, getting them perfectly right for every scenario (like casual smartphone photography) requires a lot of work. Luckily in games and adjusting it per scene it can be much easier.
The second issue is that when pushed to the extreme, the algorithm will produce artifacts. One way to get around it is to increase the number of the synthetic exposures, but this increases the cost.
Note that both of those problems don’t occur if you use it in a more “subtle” way, as a tool and in combination with other tools of the trade.
Finally, the algorithm is designed for blending LDR exposures and producing an LDR image. I think it should work with HDR pipelines as well, but some modifications might be needed.
GPU implementation
The algorithm is very straightforward to implement on the GPU. See my 300loc implementation, where those 300 lines include GUI, loading etc!
All synthetic exposures can be packed together in a single texture. One doesn’t need to create Laplacian pyramids and allocate memory for them – they can be constructed as a difference between Gaussian pyramids mip-maps. Creation of pyramids can be as simple as creating mips, or as complicated and fast as using compute shaders to produce multiple levels in one pass.
Note: I used the most simple bilinear downsampling and upsampling, which comes with some problems and would alias and flicked under motion. It also can produce diamond-shaped artifacts (an old post of mine explains those). In practice, I would suggest using a much better downsampling filter, and adjusting it for the upsampling operator. But for subtle settings this might not be necessary.
The biggest cost is in tonemapping the synthetic exposures (as expensive as your global tonemapping operator) – but one could use a simplified “proxy” operator – we care only about the correlation with the final lightness here.
Other than this, every level is just a little bit of ALU and 3 texture fetches from very low resolution textures!
How fast is it? I don’t have a way to profile it now (coding on my laptop), but I believe that if implemented correctly, it should definitely be under 1ms on even previous generation consoles.
But… we can make it even faster and make most computations happen in low resolution!
Guided upsampling
While it is doable (and possibly not too expensive) to compute the exposure fusion in full resolution, why not just compute it at lower resolution and transfer the information to the full resolution with a joint bilateral or a guided filter?
As long as we don’t filter out too much of the local contrast (in low resolution representation, sharp edges and details are missing), the results can be excellent. This idea was used in many Google research projects/products: HDRNet, Portrait mode, and for the tonemapping (it was again a fairly complex and sophisticated variation of this simple algorithm, designed and implemented by my colleague Dillon Sharlet).
I’ll refer you to my guided filter post for the details, but so far every single result that I have shown in this post was produced in ¼ x ¼ resolution and guided upsampled!
Here is a comparison of the computation at full, half, and quarter resolution, as a gif, as differences are impossible to see side-by-side:

I also had to crop as otherwise the difference was not noticeable – you can see it on the ground texture (high frequency dots) as well as a subtle smudge artifact on the chair back.
I encourage you to play with it in the demo app – you can adjust the “display_mip” parameter.
Summary
To conclude, in this post I came back to the topic of localized tonemapping, its general ideas and have described the “exposure fusion” algorithm with a simple, GPU friendly implementation – suitable for a simple WebGL demo (I release it to public domain, feel free to use or modify as much of it as you want).
It feels good to close the loop after 6y and knowing much more on the topic. 🙂
And a personal perspective – after those years, I am now even more convinced that having some LTM is a must as it’s an extremely invaluable tool. I hope this post convinced you so, and inspired you to experiment with it, and maybe implement it in your engine/game.

Hello.
Thx a lot for sharing the technique. May I ask why do you use sqrt() when compute luminance for synthetic exposure?
Also it seems like the demo is not functional ( stuck in infinite load)
I think unpkg.com might be down or slowly responsive right now. You can download the demo and change it to use offline three.js (though I am not sure how to do it, this was my first experience ever with JS packages and I have not touched it since).
Sqrt is used to simply approximate the gamma-correction/tonemapping/”perceptual” response.