

It’s been more than two decades of me using bilinear texture filtering, a few months since I’ve written about bilinear resampling, but only two days since I discovered a bug of mine related to it. 😅 Similarly, just last week a colleague asked for a very fast implementation of bilinear on a CPU and it caused a series of questions “which kind of bilinear?”.
So I figured it’s an opportunity for another short blog post – on bilinear filtering, but in context of down/upsampling. We will touch here on GPU half pixel offsets, aligning pixel grids, a bug / confusion in Tensorflow, deeper signal processing analysis of what’s going on during bilinear operations, and analysis of the magic of the famous “magic kernel”.
I highly recommend my previous post as a primer on the topic, as I’ll use some of the tools and terminology from there, but it’s not strictly required. Let’s go!
Edit: I wrote a follow-up post to this one, about designing downsampling filters to compensate for bilinear filtering.
Bilinear confusion
The term bilinear upsampling and downsampling is used a lot, but what does it mean?
One of the few ideas I’d like to convey in this post is that bilinear upsampling / downsampling doesn’t have a single meaning or a consensus around this term use. Which is kind of surprising for a bread and butter type of image processing operation that is used all the time!
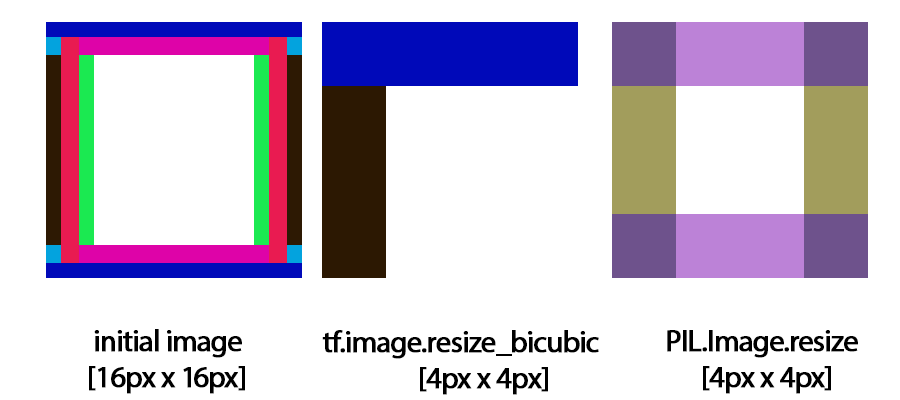
It’s also surprisingly hard to get it right even by image processing professionals, and a source of long standing bugs and confusion in top libraries (and I know of some actual production bugs caused by this Tensorflow inconsistency)!
Edit: there’s a blog post titled “How Tensorflow’s tf.image.resize stole 60 days of my life” and it’s describing same issue. I know of some of my colleagues that spent months on fixing it in Tensorflow 2 – imagine effort of fixing incorrect uses and “fixing” already trained models that were trained around this bug…
Some parts of it like phase shifting are so tricky that a famous blog post of “magic kernel” comes up every few years and again, experts re(read) it a few times to figure out what’s going on there, while the author simply rediscovered the bilinear! (Important note: I don’t want to pick on the author, far from it, as he is a super smart and knowledgeable person, and willingness to share insights is always respect worthy. “Magic kernel” is just an example of why it’s so hard and confusing to talk about “bilinear”. I also respect how he amended and improved the post multiple times. But there is no “magic kernel”.)
So let’s have a look at what’s the problem. I will focus here exclusively on 2x up/downsampling and hope that some thought framework I propose and use here will be beneficial for you to also look at and analyze different (and non-integer factors).
Because of bilinear separability, I will again abuse the notation and call “bilinear” a filter when applied to 1D signals and generally a lot of my analysis will be in 1D.
Bilinear downsampling and upsampling
What do we mean by bilinear upsampling?
Let’s start with the most simple explanation, without the nitty gritty: it is creating a larger resolution image where every sample is created from bilinear filtering of a smaller resolution image.
For the bilinear downsampling, things get a bit muddy. It is using a bilinear filter to prevent signal aliasing when decimating the input image – ugh, lots of technical terms. I will circle back to it, but first address the first common confusion.
Is this box or bilinear downsampling? Two ways of addressing it
When downsampling images by 2, we every often use terms box filter and bilinear filter interchangeably. And both can be correct. How so?
Let’s have a look at the following diagram:

We can see that a 2 tap box filter is the same as a 2 tap bilinear filter. The reason for it is that in this case, both filters are centered between the pixels. After discretizing them (evaluating filter weights at sample points), there is no difference, as we no longer know what was the formula to generate them, and how the filter kernel looked outside of the evaluation points.
The most typical way of doing bilinear downsampling is the same as box downsampling. Using those two names for 2x downsampling interchangeably is both correct! (Side note: Things diverge when taking about more than 2x downsampling. This might be a good topic for another blog post.) For 1D signals it means averaging every two elements together, for 2D images averaging 4 elements to produce a single one.
You might have noticed something that I implicitly assumed there – pixel centers there were shifted by half a pixel, and the edges/corners were aligned.
There is “another way” of doing bilinear downsampling, like this:

This one definitely and clearly is also a linear tent, and it doesn’t shift pixel centers. The resulting filter weights of [0.25 0.5 0.25] are also called a [1 2 1] filter, or the simplest case of a binomial filter, a very reasonable approximation to a Gaussian filter. (To understand why, see what happens to the binomial distribution as the trial count goes to infinity!). It’s probably the filter I use the most in my work, but I digress. 🙂
Why this second method is not used that much? This is by design and a reason for half texel shifts in GPU coordinates / samplers, and you might have noticed the problem – the last texel of high resolution array gets discarded. But let’s not get ahead of ourselves, first we can have a look at the relationship with upsampling.
Two ways of bilinear upsampling – which one is “proper”?
If you were to design a bilinear upsampling algorithm, there are a few ways to address it.
Let me start with a “naive” one that can have problems. We can take every original pixel, and between them just place averages of the other ones.

Is it bilinear / tent? Yes, it’s a tent filter on zero-inserted image (more on it later). It has an unusual property; some pixels get blurred, some pixels stay “sharp” (original copied).
But more importantly, if you do box/bilinear downsampling as described above, and then upsample an image, it will be shifted:

Or rather – it will not correct for the half pixel shift created by downsampling.
It will work however with downsampling using the second method. The second method interpolates every single output pixel; all are interpolated:

This another way of doing bilinear upsampling that might first feel initially unintuitive: every pixel is 0.75 of one pixel, and 0.25 of another one, alternating “to the left” and “to the right”. This is exactly what a GPU does when you upsample a texture by 2x:

There are two simple explanations for those “alternating” weights. The first, easiest one is just looking at the “tents” in this scheme:

I’ll have a look at the second interpretation of this filter – it’s [0.125 0.375 0.375 0.125] in disguise 🕵️♀️, but first with this intro, I think it’s time to make the main claim / statement: we need to be careful to use same reference coordinate frames when discussing images of different resolutions.
Be careful about phase shifts
Your upsampling operations should be aware of what downsampling operations are and how they define the pixel grid offset, and the other way around!
Even / odd filters
One important thing to internalize is that signal filters can have odd or even number of samples. If we have an even number of samples, such a filter doesn’t have a “center”, so it has to shift the whole signal by a half pixel in either direction. By comparison, symmetric odd filters can shift specific frequencies, but don’t shift the whole signal:

If you know signal processing, those are the type I and II linear phase filters.
Why shifts matter
Here’s a visual demonstration of why it matters. A Kodak dataset image processed with different sequences, first starting with box downsampling:
And now with [1 2 1] tent odd downsampling:

If there is a single lesson from my post, I would like it to be this one: Both “takes” on the bilinear up/downsampling above can be the valid and correct ones, you simply need to pick the proper one for your use-case and the convention used throughout your code/frameworks/libraries; always use a consistent coordinate convention for the downsampling and upsampling. When you see term “bilinear”, always double check what it means! Because of it, I actually like to reimplement those and be sure that I’m consistent…
That said, I’d argue that the “box” bilinear downsampling and the “alternating weights” are better for average use-case. The first reason might be somewhat subjective / minor (because bilinear down/upsampling is inherently low quality and I don’t recommend using it when the quality matters more than simplicity / performance). If we visually inspect the upsampling operation, we can see more leftover aliasing (just look at the diagonal edges) in the odd/odd combo:

The second reason, IMO a more important one is how easily they align images. And this is why GPU sampling has this “infamous” half a pixel offset.
That half pixel offset!
Ok, so my favorite part starts – half pixel offsets! Source of pain, frustration, misunderstanding, but also a super reasonable and robust way of representing texture and pixel coordinates. If you started graphics programming relatively recently (DX10+ era) or are not a graphics programmer – this might be not a big deal for you. But basically, with older graphics APIs framebuffer coordinates didn’t have a half texel offset, while the texture sampler expected it, so you had to add it manually. Sometimes people added it in the vertex shader, sometimes in the pixel shader, sometimes setting up uniforms on the CPU… a complete mess; it was a source of endless bugs found almost every day, especially on video games shipping on multiple platforms / APIs!
What do we mean by half pixel offset?
If you have a 1D texture of size 4, what are your pixel/texel coordinates?
They can be [0, 1, 2, 3]. But GPUs use a convention of half pixel offsets, so they end up being [0.5, 1.5, 2.5, 3.5]. This translates to UVs, or “normalized” coordinates [0.5/4, 1.5/4, 2.5/4, 3.5/4], which spans a range of [0.5/width, 1 – 0.5/width].
This representation seems counterintuitive at first, but what it provides us is a guarantee and convention that the image corners are placed at [0 and 1] normalized, or [0, width] unnormalized.
This is really good for resampling images and operating on images with different resolutions.
Let’s compare the two on the following diagrams:


While the half a pixel align pixel corners, the other way of down/upsampling comes from aligning the first pixel centers in the image.
Now, let’s have a look at how we compute the bilinear upsampling weights in the half a pixel shift convention:

This convention makes it amazingly simple and obvious where the weights come from – and how simple the computation is once we align the grid corners. I personally use it as well even in APIs outside of GPU shader realm – everything is easier. If adding and removing 0.5 adds performance cost, then can be removed at microoptimizations stage, but usually doesn’t matter that much.
Reasonable default?
Half a pixel offset for pixel centers used in GPU convention for both pixels and texels is a reasonable default for any image processing code dealing with images of different resolutions.
This is expecially important when to dealing with textures of different resolutions and for example mip maps of non power of 2 textures. A texture with 9 texels instead of 4? No problem:

It makes sure that grids are aligned, and the up/downsampling operations “just work”. To get box/bilinear downsampling, you can just take a single bilinear tap of the source texture, the same with the upsampling.
So trivial to use it that when you start graphics programming, you rarely think about it. Which is a double edge sword – both great for an easy entry point for beginners, but also a source of confusion once you start getting deeper into it and analyzing what’s going on or do things like fractional or nearest neighbor downsampling (or e.g. create a non-interpolable depth map pyramid…).
Even if there were no other reasons, this is why I’d recommend treating phase shifting box downsample and the [0.25 0.75] / [0.75 0.25] upsamplers as your default when talking about bilinear as well.
Bonus advantage: having texel coordinates shifted by 0.5 means that if you want to get an integer coordinate – for example for texelFetch instruction – you don’t need to round. Floor / truncation (which in some settings can be a cheaper operation) gives you the closest pixel integer coordinate to index!
Note: Tensorflow got it wrong. The “align_corners” parameter aligns… centers of the corner pixels??? This is a really bad and weird naming plus design choice, where upsampling a [0.0 1.0] by factor of 2 produces [0, 1/3, 2/3, 1], which is something completely unexpected and different from either of the conventions I described here.
Signal processing – bilinear upsampling
I love writing about signal processing and analyzing signals also in the frequency domain, so let me explain here how you can model bilinear up/downsampling in the EE / signal processing framework.
Upsampling usually is represented as two operations: 1. Zero insertion and 2. Post filtering.
If you never heard of this way of looking at it (especially the zero insertion), it’s most likely because in practice nobody in practice (at least in graphics or image processing) implements it like this, it would be super wasteful to do it in such a sequence. 🙂
Zero insertion
Zero insertion is an interesting, counter-intuitive operation. You insert zeros between each element (often multiplying the original ones by 2x to preserve the constant/average energy in the signal; or we can fold this multiplication in our filter later) and get 2x more samples, but they are not very “useful”. You have an image consisting of mostly “holes”…

I think that looking at it in 1D might be more insightful:

From this plot, we can immediately see that with zero insertion, there are many high frequencies that were not there! All of those zeros create lots of high frequency coming from alternating and “oscillating” between the original signal, and zero. Filters that are “dilated” and have zeros in between coefficients (like a-trous / dilated convolution) are called comb filters – because they resemble a comb teeth!
Let’s look at it from the spectral analysis. Zero insertion duplicates the frequency spectrum:

Every frequency of the original signal is duplicated, but we know that there were no frequencies like this present in the smaller resolution image; it wasn’t possible to represent anything above its Nyquist! To fix that, we need to filter them out after this operation with a low pass filter:

I have shown some remainder frequency content on purpose, as it’s generally hard to do “perfect” lowpass filtering (and it’s also questionable if we’d want this – ringing problems etc).
Here is how progressively filtered 1D signal looks like, notice high frequencies and “combs” disappearing:

Here’s an animation of blurring/filtering on the 2D image and how there it also causes this zero-inserted image to become more and more like just properly upsampled:

Looks like image blending, but it’s just blending filters – imo it’s pretty cool. 😎
Nearest neighbor -> box filter!
Obviously, the choice of the blur (or technically – lowpass) filter matters – a lot. Some interesting connection: what if we convolve this zero-inserted signal with a symmetric [0.5, 0.5] (or 1,1 if we didn’t multiply the signal by 2 when inserting zeros) filter?


The interesting part here is that we kind of “reinvented” the nearest neighbor filter! After a second of though, this should be intuitive; a sample that is zero gets contributions from the single non-zero neighbor, which is like a copy, while the sample that is non-zero is surrounded by two zeros, and they don’t affect it.
We can see on the spectral / Fourier plot where the nearest neighbor hard edges and post-aliasing comes from (red part of the plot):

The nearest neighbor upsampling is also shifting the signal (because it is even number of samples) and will work well to undo the box downsampling filter, which fits the common intuition of replicating samples being the “reverse” of box filtering and causing no shift problem.
Bilinear upsampling take one – direct odd filter
Let’s have a look at how the strategy of “keep one sample, interpolate between” can be represented in this framework.
It’s equivalent to filtering our zero-upsampled image with a [0.25 0.5 0.25] filter.
The problem is that in such setup, if we multiply the weights two (to keep average signal the same) and then by zeros (where the signal is zero), we get alternating [0.0 1.0 0.0] and [0.5 0.0 0.5] filters, with very different frequency response and variance reduction… I’ll reference you here again to my previous blog post on it, but basically you get alternating 1.0 and 0.5 of original signal variance (sum of effective weights squared).
Bilinear upsampling take two – two even filters
The second approach of alternating weights of [0.25 0.75] can be seen as simply: nearest neighbor upsampling – a filter of [0.5 0.5], and then [0.25 0.5 0.25] filtering!
This sequence of two convolutions gives us an effective kernel of [0.125 0.375 0.375 0.125] on the zero inserted image, so if we multiply it by 2 simply alternating [0.25 0.0 0.75 0.0] and [0.0 0.75 0.0 0.25]. Corners aligned bilinear upsampling (standard bilinear upsampling on the GPU) is exactly the same as the “magic kernel”! 🙂 This is also this second, more complicated explanation of bilinear 0.25 0.75 weights I promised.
Advantage of it is that with the effective weight of [0.25 0.75] and [0.75 0.25] (ignoring zeros) on alternating pixels, they have the same amount of filtering and variance reduction of 0.625 – very important!
This is how the combined frequency response compares to the previous one:

So as expected, more blurring, less aliasing, consistent behavior between pixels.
Neither is perfect, but the even one will generally cause you less “problems”.
Signal processing – bilinear downsampling
By comparison, downsampling process should be a bit more familiar to readers who have done some computer graphics or image processing and know of aliasing in this context.
Downsampling consists of two steps in opposite order: 1. Filtering the signal. 2. Decimating the signal by discarding every other sample.
The ordering and step no 1 is important, as the second step, decimating is equivalent to (re)sampling. If we don’t filter the signal spectrum above frequencies representible in the new resolution, we are going to end up with aliasing, folding back of frequencies above previous half Nyquist:

This is the aliasing the nearest-neighbor (no filtering) image downsampling causes:

Bilinear downsampling take one – even bilinear filter
First antialiasing filter we’d want to analyze would be our old friend “linear in box disguise”, [0.5, 0.5] filter. It is definitely imperfect, and we can see both blurring, and some leftover aliasing:

The Graphics community realized this a while ago – when doing a series of downsamples for post-processing, for example bloom / glare; the default box/tent/bilinear filters are pretty bad in such case. Even small aliasing like this can be really bad when it gets “blown” to the whole screen, and especially in motion. It was even a large chunk of Siggraph presentations, like this excellent one from my friend Jorge Jimenez.
I also had a personal stab at addressing it early in my career, and even described the idea – weird cross filter (because it was fast on the GPU) – please don’t do it, it’s a bad idea and very outdated! 🙂
Bilinear downsampling take two – odd bilinear filter
By comparison the odd bilinear filter (that doesn’t shift the phase) looks like a little different trade-off:

Less aliasing, more blurring. It might be better for many cases, but the trade-offs from breaking the half-pixel / corners aligned convention are IMO unacceptable. And it’s also more costly (not possible to do a single tap 2x downsampling).
To get better results -> you’ll need more samples, some of them with negative lobes. And you can design an even filter with more samples too, for example even Lanczos:

Side note – different trade-offs for up/downsampling?
One interesting thing that has occurred to me on a few occasions is that the trade-offs for low pass filtering for upsampling and downsampling are different. If you use a “perfect” upsampling lowpass filter, you will end up with nasty ringing.
This is typically not the case for downsampling. So you can opt for a sharper filter when downsampling, and a less sharp for upsampling, and this is what Photoshop suggests as well:

Conclusions
I hope that my blog post helped to clarify some common confusions coming from using the same, very broad terms to represent some different operations.
A few of main takeaways that I’d like to emphasize would be:
- There are a few ways of doing bilinear upsampling and downsampling. Make sure that whatever you use uses the same convention and doesn’t shift your image after down/upsampling.
- Half pixel center offset is a very convenient convention. It ensures that image borders and corners are aligned. It is default on the GPU and happens automatically. When working on the CPU/DSP, it’s worth using the same convention.
- Different ways of upsampling/downsampling have different frequency response, and different aliasing, sometimes varying on alternating pixels. If you care about it (and you should!), look more closely into which operation you choose and optimal performance/aliasing/smoothing tradeoffs.
I wish more programmers were aware of those challenges and we’d never again again hit bugs due to inconsistent coordinate and phase shifts between different operations or libraries… I also with we could never see those “triangular” or jagged aliasing artifacts in images, but bilinear upsampling is so cheap and useful, that instead we should be just simply aware of potential problems and proactively address them.
To finish this section, I would again encourage you to read my previous blog post on some alternatives to bilinear sampling.
PS. What was my bug that I mentioned at beginning of the post? Oh, it was simple “off by one” – in numpy when convolving with np.signal.convolve1d and 2d I assumed wrong “direction” of the convolution of even filters. Subtle bug, but it was shifting everything by one pixel after sequence of downsamples and upsamples. Oops. 😅

There seem to be an error in the second figure:
“2 tap box filter is the same as a 2 tap bilinear filter”
The 2 tap bilinear is incorrect.
The “tents” wouldn’t overlap properly and the weights don’t sum to 2 (0.75+0.75).
The correct position for the foot of the tent must be at a pixel boundary, which would give you the “magic kernel” weights of [0.25,0.75,0.75,0.25]
This is not an error, this is for *downsampling*. And my point is exactly that they are the same; have you read the text?
Perhaps I sounded too argumentative so you didn’t try to understand what I wrote. I didn’t mean to sound dismissive, you’re addressing an important problem here. However, you’re showing on the left a tent filter as a bilinear kernel (which I agree with) but I believe you’re setting the width of that kernel to be incorrect. To be clear: Yes, modelling bilinear downsampling with a tent filter is correct, but the width of that filter needs to be set correctly. In your case the width of a 2x downsampling kernel is incorrectly set to be 3 pixels wide, and as a result you get weights [0.75 0.75] which you then seem normalise to [1,1] to say that they are equivalent to a box filter of [1,1]. However, if you set the kernel width correctly to be 4 pixels wide (resulting in the weights [0.25,0.75,0.75,0.25]) you don’t need to normalise and you don’t have an equivalence anymore. This might be an important part of your argument.
no, you still don’t follow my argument – I am describing what actually happens on the GPU with bilinear/tent filter. This is exactly what you get, equivalence of box and tent filter. Not a hypotetical scenario. Not [0.25, 0.75, 0.75, 0.25] filter, but [0.5, 0.5].
And if you read my post, the whole idea is that of having filter 1, 2, 3, 4, 100 pixels wide is 100% up to you. Downsampling is “some” filter (or no filter), and then decimation.
That’s clearer, thank you. I find that surprising. It might be worth mentioning in the text what bilinear algorithm implemetation you’re describing there. For example, if I use Tensorflow 2’s (now fixed) bilinear filter it’s working like I described. You can try it yourself:
>>> V = tf.reshape([0,0,0,8,0,0,0,0], [8,1,1])
>>> U = tf.image.resize(V, [4,1],method=tf.image.ResizeMethod.BILINEAR, antialias=True)
At the end U[:,0,0] is [0,3,1,0], from which you can work out that the resampling used a [1,3,3,1] filter.
antialias=True forces the use of a tent filter instead of taking a single bilinear sample. Are you sure when you tried a bilinear downscale on the GPU it was doing an actual tent filter and wasn’t just taking a single bilinear sampe from the image? Because then it would behave exactly as a box filter when you’re 2x downscaling.
p.s.: At the very least I’m helping you emphasize your point that “bilinear upsampling / downsampling doesn’t have a single meaning or a consensus around this term use”. You’re welcome 🙂
The half pixel offset is natural and makes sense. Just keep it simple guys. I think of it in how the GPU samples textures. The center of a pixel is always 0.5f from its edge, Sample the center and you actually sample 0.5f of the pixels around (above,below,right,left) (4 pixels) –if your using the regular texture() GLSL function (bilinear sampling enabled aswell)..
Or if using texelFetch, well that gets you just one pixel., and that pixel if sampled at it’s center is exactly that – one pixel. Oh I love how you mentioned there is no need to round/floor – keep it simple!
Great article Bart
Thanks for the article and diagrams! I was about to get upsampling wrong.
Pingback: Computing gradients on grids – forward, central, and… diagonal differences | Bart Wronski
Pingback: Processing aware image filtering: compensating for the upsampling | Bart Wronski
Pingback: Practical Gaussian filtering: Binomial filter and small sigma Gaussians | Bart Wronski
Pingback: Exposure Fusion – local tonemapping for real-time rendering | Bart Wronski
Pingback: Fast, GPU friendly, antialiasing downsampling filter | Bart Wronski
The fact that a naive bilinear downsample is equivalent to a box filter is a huge detriment to image quality. An “academically proper” radius of 1 pixel (a span of 4 pixels at the source) at the target resolution avoids the pitfalls of box filtering. I actually strongly prefer it to bicubic sampling as it doesn’t lead to wobbling due to an uneven motion of energy concentration from pixel to pixel.
It also lends itself well to mini particle/star rendering. You can render a quad from a sprite point and linearly interpolate to the nearest pixels to effectively get perfect bilinear anti-aliasing. It looks super stable in motion while remaining sharp.