

In this blog post I am going to describe some of my past investigations on reducing the number of channels in textures / texture sets automatically and generally – without assuming anything about texture contents other than correspondence to some physical properties of the same object. I am going to describe the use of Singular Value Decomposition (a topic that I have blogged about before) / Principal Component Analysis for this purpose.
The main use-case I had in mind is for Physically Based Rendering materials with large sets of multiple textures representing different physical material properties (often different sets per different material/object!), but can be extended to more general images and textures – from simple RGB textures, to storing 3D HDR data like irradiance fields.
As usually, I am also going to describe some of the theory behind it, a gentle introduction on a “toy” problems and two examples on simple RGB textures from Kodak dataset, before proceeding to the large material texture set use-case.
Note: There is one practical, significant caveat of this approach (related to GPU block texture compression) and a reason why I haven’t written this post earlier, but let’s not get ahead of ourselves. 🙂
This post comes with three colabs: Part 1 – toy problem, Part 2 – Kodak images, Part 3 – PBR materials.
Intro – problem with storage of physically based rendering materials
I’ll start with a confession – this is a blog post that I was aiming to write… almost 3 years ago. Recently a friend of mine asked me “hey, I cannot find your blog post on materials dimensionality reduction, did you end up writing it?” and the answer is “no”, so now I am going to make up for it. 🙂
The idea for it came when I was still working on God of War and one of the production challenges was disk and memory storage cost for textures and materials. Without going into details on what were the challenges of our specific material system and art workflows, I believe this is a challenge for all contemporary AAA video games – simply physically based rendering type of workflows requires a lot of textures – stressing not only the BluRay disk capacities, but also the gamers are not happy about downloading tens of gigabytes of just patches…
To list a few example different textures used per a single object/material (note: probably no single material used all of them, some of them are rare, but I have seen all in production):
- Albedo textures,
- Specularity or specular color textures,
- Gloss maps,
- Normal maps,
- Heightmaps for blending or parallax mapping,
- Alpha/opacity maps for blending,
- Subsurface or scattering color,
- Ambient occlusion maps,
- Specular cavity maps,
- Overlay type detail maps.
Uff, that’s a lot! And some of those use more than one texture channel! (like albedo maps that use RGB colors, or normal maps that are usually stored in two or three channels). Furthermore, with increasing target screen resolutions, textures also need to be generally larger. While I am a fan of techniques like “detail mapping” and using masked tilers to avoid the problem of unique large textures everywhere, those cannot cover every case – and the method I am going to describe applies to them as well.
All video games use hardware accelerated texture block compression, and artists manually decide on the target resolution of different maps. It’s time consuming, not very creative, and fighting those disk usage and memory budgets is a constant production struggle – not just for the texture streaming or fitting on a BluRay disk, but also the end users don’t want to download 100s of GBs…
Could we improve that? I think so, but before we go to the material texture set use-case, let’s revisit some ideas that apply to “images” in more general sense.
Texture channels are correlated
Let’s start with a simple observation – all natural images have correlated color channels. “Physical” explanation for it is simple – no matter what is the color of the surface, when it is lit, its color is modulated by the light (in fact by the light spectrum and after interacting with its surface through BRDF, but let’s keep our mental model simple!). This means that all of those color channels will be at least partially correlated, and light intensity / luminance modulates whatever was the underlying physical surface (and vice versa).
What do you mean by “correlated” color channels and how to decorrelate them?
Let’s look at a contrived example – list of points representing pixels in a two color (red and green) channel texture to keep visualization in 2D. In this toy scenario we can observe a high correlation between red and green in the original red/green color space. What does this mean? If the value of green channel brightness is high, it is also very likely that the red channel will is also high. On the following plot, every dot represents a pixel of an image positioned in the red/green space on the left:
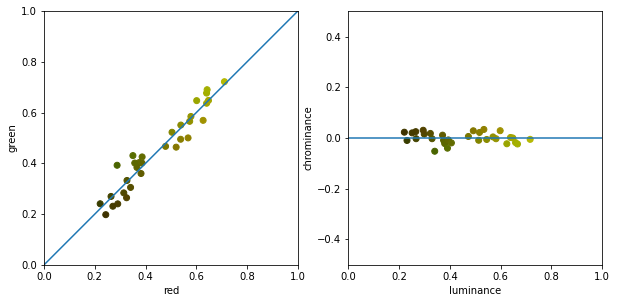
On the right plot, I have projected those on the blue line, representing something like luminance (overall brightness).
We can see that from the original signal which was changing a lot on both axis, after projecting onto luminance axis, we end up with significantly less variation and no correlation on the perpendicular “chrominance” (here defined as simple difference of red and green channelvalues) axis. Decorrelated color space means that values of a single channel are not dependent or linearly related to the values of another color channel. (There could be a non-linear relationship, but I am not going to cover it in this post and it becomes significantly more difficult to analyze, requiring iterative or non-linear methods.)
This property is useful for compression, as while the original image needed for example 8 bits for both red and green color channels, in the decorrelated space we can store the other axis with a significantly smaller precision – there is much less variation, so possibly 1-2 bits would suffice, or we could store it in smaller resolution.
This is one of the few reasons why we use formats like YUV for encoding, compressing and sending images and videos. (As a complete offtopic, three other reasons that come to my mind right now are also interesting – human visual perception system being less perceptive to color changes and allowing for more compression of color; chroma varying more smoothly (less high frequencies) in natural images; and finally for now obsolete now historical reasons, where old TVs needed “backwards compatibility” requiring transmitted signal to be possible to view on black&white old TVs ).
Let’s have a look at two images from Kodak dataset in RGB and YUV color spaces. I have deliberately picked one image with many different colors (greenish water, yellow boat, red vests, blue shorts, green and white tshirts), and the other one relatively uniform (warm-green white balance of an image with foliage):


It’s striking how much of the image content is encoded just in the Y, luminance color channel! You can fully recognize the image from the luminance, while chrominance is much more “ambiguous”, especially on the second picture.
But let’s look at it more methodically and verify – let’s plot the absolute value of the correlation matrices of color channels of those images.

This plot might deserve some explanation: Value of 1 means fully correlated channels (as expected on the diagonal – variable is fully correlated with itself).
Value of zero means that two color channels don’t have any linear correlation (note – there could be some other correlation, e.g. quadratic!) and the matrices are symmetric, as the red color channel has same correlation with the green as the green with the red one.
First picture, with more colors has significantly less correlation between color channels, while the more uniformly colored one shows very strong correlation.
I claimed that YUV generally decorrelates color channels, but let’s put this to a test:

The YUV color space decorrelated more colorful image to some extent, while the less colorful one got decorrelated almost perfectly.
But let’s also see how much information is in every “new” channel with displaying absolute covariances (one can think of covariance matrix as correlation matrix multiplied by variances):
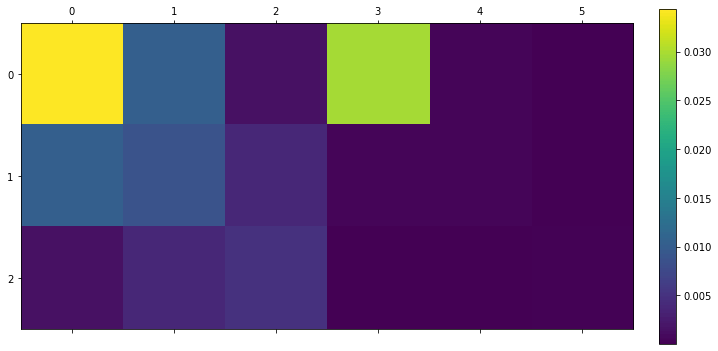
In those covariance plots we can verify our earlier intuition/observation that the luminance represents the image content/information pretty well and most of it is concentrated there.
Now, the Y luminance channel is created to roughly correspond to perception of the brightness of the human vision. There are some other color spaces like YCoCg that are designed for more decorrelation (as well as better computational efficiency).
But what if we have some correlation, but not along this single axis? Here’s an example:

Such a fixed axis doesn’t work very well here – we have somewhat reduced the ranges of variation, but there is still some “wasteful” strong linear correlation…
Is there some transformation that would decorrelate them perfectly while also providing us with the “best” representation for a given subset of components? I am going to describe a few different “angles” that we can approach the problem from.
Line fitting / least squares vs dimensionality reduction?
The problem as pictured above – finding best line fits – is simple. In theory, we could do some least squares linear fit there (similarly to what I described in my post on guided image filters). However, I wanted to strongly emphasize that line fitting is not what we are looking for here. Why so? Let’s have a look at the following plot:

Least squares line fitting will minimize the error and fit for the original y axis (as it is written to minimize the average “residual” error a*x+b – y), while what we are looking for is a projection axis with smallest error when the point is projected on that line! In many cases those lines might be similar, but in some they might be substantially different.
Here’s an example on a single plot (hopefully still “readable”):

For the case of projection, we want to minimize the component perpendicular to the projection axis, while linear line fitting / linear least squares minimize the error measured in the y dimension. Those are very different theoretical (and also practical when the number of dimensions grows) concepts!
In the earlier plot I mentioned name PCA, which stands for Principal Component Analysis. It is a technique for dimensionality reduction – something that we are looking for.
Instead of writing how to implement PCA with covariance matrices etc., (it is quite simple and fun to derive it using Lagrange multipliers, so might write a separate post on it in future) I wanted to look at it from a different perspective – of Singular Value Decomposition, which I blogged about in the past in the context of filter separability
I recommend that post of mine if you have not seen it before – not because of its relevance (or my arrogance), but simply as it describes a very different use of SVD. I think that seeing some very different use-cases of mathematical tools, concepts, and their connections is the best way to understand them, build intuition and potentially lead to novel ideas. As a side note – in linear algebra packages, PCA is usually implemented using SVD solvers.
Representing images as matrices – image doesn’t have to be a width x height matrix!
Before describing how we are going to use SVD here, I wanted to explain how we want to represent N-channel images by matrices.
This is something that was not obvious to me, and even after seeing it, defaulting to thinking about it in different ways took me years. The “problem” is that usually in graphics we immediately think of an image as a 2D matrix – width and height of the image get represented with matrix width and height; simple adding color channels immediately poses a problem, as it requires a 3D tensor. This thinking is very limited, only one of few possible representations and arguably a not very useful one. It took me quite a while to stop thinking about it this way and it is important even for “simple” image filtering (bilateral filter, non-local means etc.).
In linear algebra, matrices represent “any” data. How we use a matrix to represent image data is up to us – but most importantly, up to the task and goal we want to achieve. Representation that we are going to use doesn’t care for spatial positions of pixels – they don’t even have to be placed on an uniform grid! Think of them just as “some samples somewhere”. For such use-cases, we can represent the image as all different pixel positions (or sample indices) on one axis, and color channels on the other axis.
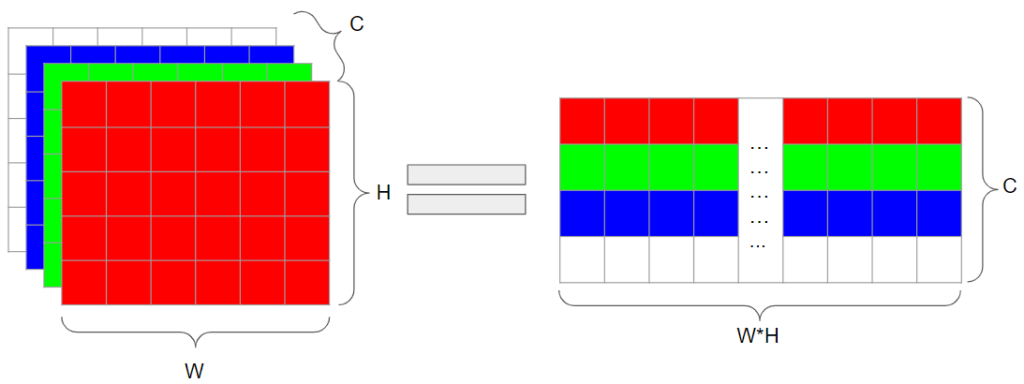
This type of thinking becomes very important when talking about any kind of processing of image patches, collaborative filtering etc. – we usually “flatten” patch (or whole image) and pack all pixels on one axis. If there is one thing that I think is particularly important and worth internalizing from my post – it is this notion of not thinking of images as 2D matrices / 3D tensors of width x height pixels.
Important note – as long as we remember the original dimensions and sample locations, those two representations are equivalent and we can (and are going to!) transform back and forth between them.
This approach extends to 3D (volumetric textures), 4D (volumetric videos) etc. – we can always pack width * height * depth pixels along one axis.
SVD of image matrices
We can perform the Singular Value Decomposition of any matrix. What do we end up with for the case of our image represented as a w*h x c matrix?
(Note: I tried to be consistent with ordering of matrices and columns / rows, but it’s usually something that I trip over – but in practice it doesn’t matter so much as you can transpose the input matrix and swap the U and V matrices.)
The SVD is going to look like:

Oh no, instead of a single matrix, we ended up with three different matrices, one of which is as big as the input! How does this help us?
Let’s analyze what those matrices represent and their properties. First of all, matrix U represents all of our pixels in our new color space. We still have C channels, but they have different “meaning”. I used color coding of “some” colors to emphasize that those are not our original colors anymore.
Those new C channels contain different amount of energy / information and have different “importance”. Amount of it is represented in the diagonal S matrix, with decreasing singular values. The first new color channel will represent the largest amount of information about our original image, the next channel less etc. (Note the same used colors as in matrix U).
Finally, there is a matrix V that transforms between the new color channels space, and the old one. Now the most important part – this transformation matrix is orthogonal (and even further, orthonormal). It means that we can think of it as a “rotation” from the old color space, to the new one, and every next dimension provides different information without any “overlap” or correlation. I used here “random” colors, as those represent weights and remappings from the original, RGBA+other channels, to the new vector space.
Now, together matrices T and S inform us about transforming image data into some color space, where channels are orthogonal, and sorted by their “importance”, and where first k components are “optimal” in terms of contained information (see Eckart–Young theorem).
Edit / bonus section: A few readers have commented in a thread on twitter (and on Facebook) that while Eckart-Young is from perspective of linear algebra, usually image compression and stochastic processes analysis use the name Karhunen–Loève theorem/transform. It is a concept that is new to me (as I have not really worked with neither of those fields) and I have to and will be happy to read more about it. Thanks to everyone for pointing out this connection, always excited to learn some new concepts!
Think of it as rotating input data to a perfectly decorrelated linear space, with dimensions sorted based on their “importance” or contribution to the final matrix / image, and fully invertible – such representation is exactly what we are looking for.
How does it relate to my past post on SVD?
A question that you might wonder is – in my previous post, I described using SVD for analyzing separability and finding approximations of 2D image filters – how does this use of SVD relate to the other?
We have looked in the past at singular components, sorted by their importance, combined with single rows + columns reconstructing more and more of the original filter matrix.
Here we have a similar situation, but our U “rows” are all pixels of the image, every one with single channel, and V “columns” are combinations of the original input channels that transform to this new channel space. Just like before, we can add singular values multiplied by the corresponding vectors one by one, to get more and more accurate representation of the input (no matter whether it’s a filter matrix or a flattened representation of an image). The first singular value and color combination will tell us the most about the image, the next tells a bit less less information etc. Some images (with lots of correlation) have huge disproportion of those singular values, while in some other ones (with almost no correlation) they are going to be decaying very slowly.
This might seem “dry” and is definitely not exhaustive. But let’s try to build some intuition for it by looking at the results of SVD on our “toy” problem. If we run it on toy problem matrix image data as it is, we will immediately encounter a limitation that is easy to address:

The line corresponding to the first singular value passes nicely through the cluster or our data points (unlike simple “luminance”), however clearly doesn’t decorrelate points – we still see some simple linear relationship in the transformed data.
This is a bit disappointing, but there is a simple reason for it – we ran SVD on original data, fitting a line/projection, but also forcing it to go through original zero!
Usually when performing PCA or SVD in the context of dimensionality reduction, we want to remove the mean of all input dimensions, effectively “centering” the data. This way we can “release” the line intercept. Let’s have a look:

As presented, shifting the fit center to the mean of the data, shifts the line fit and achieves perfect “decorrelating” properties. PCA that runs on covariance matrices does this centering implicitly, while in the case of SVD we need to do it manually.
In general, we would probably want to always center our data. For compression-like scenarios it has an additional benefit that we need to compress only the “residual”, so difference between local color, and the average for the whole image, making the compression and decompression easier at virtually no additional cost.
In general, many ML applications go even step further, and “standardize” the data, bringing it to the same range of values by dividing them by their standard deviations. For many ML-specific tasks this makes sense, as for tasks like recognition we don’t really know the importance of ranges of different dimensions / features. For example if someone was writing a model to recognize a basketball player based on their weight, height, and maybe average shot distance, we don’t want to get different answers depending on whether we enter the player’s weight in kilograms vs pounds!
However for tasks like we are aiming for – dimensionality reduction for “compression” we want to preserve the original ranges and meanings, and can assume that they are already scaled based on their importance. We can take it even further and use the “importance” to guide the compression, and I will describe it briefly around the end of my post.
SVD on Kodak images
Equipped with knowledge on how SVD applies to decorrelating image data, let’s try it on the two Kodak pictures that we analyzed using simple YUV transformations.
Let’s start with just visualizing both images in the target SVD color space:

Results of projection seem to be generally very similar to our original YUV decomposition, with one main difference is that our projected color channels are “sorted”. But we shouldn’t just “eyeball” those, instead we can analyze this decomposition numerically.
Covariance matrices and singular values
Comparing covariance matrices (and square roots of those matrices – just for visualization / “flattening”) shows the real difference between such a pretty good, but “fixed” basis function like YUV, and a decorrelated basis found by SVD:
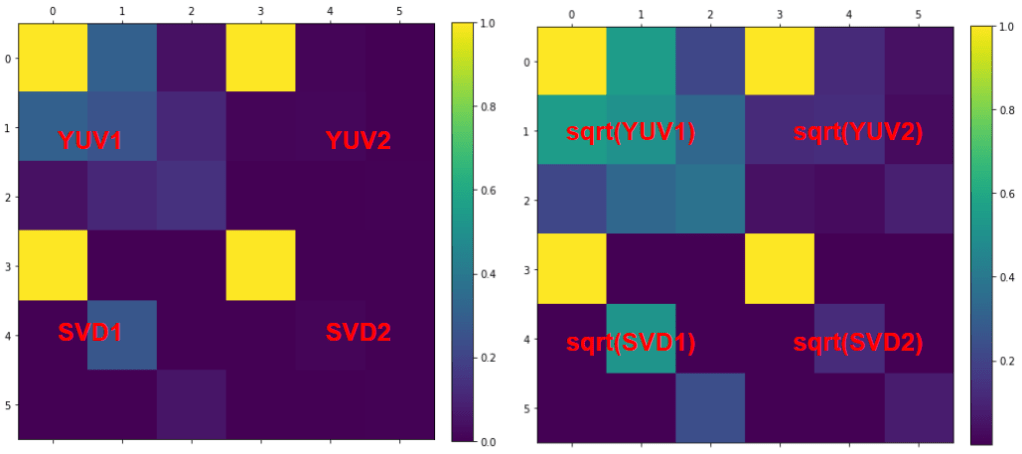
As expected, SVD fully decorrelates the color channels. We can also look at how the singular values for those images decay:

So again, hopefully it’s clear that with SVD we get faster decay of the “energy” contained in different image channels – the first N channels will reconstruct the image better. Let’s look at the visual example.
Visual difference when keeping only two channels
To fully appreciate the difference, let’s look at how the images would look like if we used only two channels – YUV vs SVD and corresponding PSNRs:

The difference is striking visually, as well as very significant numerically.
This shouldn’t come as a surprise, as SVD finds a reparametrization / channel space that is the “best” projection for thr L2 metric (which is also used for PSNR computations), decorrelates, and sorts this space according to importance.
I wonder why JPEG wouldn’t use such decomposition – I would be very curious to read in the comments! :)I have two guesses of mine: JPEG is an old color format with lots of “legacy” and support in hardware – both encoders, as well as decoders. A single point-wise floating point matrix multiply (where matrix is just 4×3 – 3×3 multiplication and adding back means) seems super cheap to any graphics programmers, but would take a lot of silicon and power to do efficiently in hardware. A second guess is related to the “perceptual” properties of chrominance (and worse human vision sensitivity to it) – SVD doesn’t guarantee us that decomposition will happen in the rough direction of luminance, could be “any” direction.
Edit / addendum: While my remark re JPEG was about the YUV luminance/chrominance decomposition as compared to doing PCA on the color channels, the use of DCT basis for the spatial compression component (instead of mentioned before KLT and eigendecomposition of data directly) is considered “good enough”, and I learned from a reply twitter thread with Per Vognsen and Fabian Giesen about some justifications for its use and another set of connections to stochastic processes.
Now, this use case – decorrelating RGB channels – can be very useful not for standard planar image textures, but also for 3D volumetric colored textures. I know that many folks store and quantize/compress irradiance fields in YUV-like color spaces, and using there SVD will most likely have better quality/compression ratios. This would become even more beneficial for storing sky / ambient occlusion in addition to the irradiance, and one of the further section includes an example AO texture (albeit for the 2D case).
Relationship to block texture compression
If you have worked with GPU “block texture compression” (like DXT / BC color formats) you can probably recognize some of the described concepts – in fact, the simplest BC1 format does a PCA/SVD and finds a single axis, on which colors are projected! I recommend Nathan Reed’s blog post on this topic and a cool visualization.
This is done per a small, 4×4 block and because of that, we can expect much more energy be stored in the single component. This is a visualization of how such BC compression would +/- look like with our toy problem:

Any blocks that don’t have almost all of information in the first singular value (so are not constant or have more than a single gradient) are going to end up with discoloration and block artifacts – but since we talk about just 4×4 blocks, GPU block compression usually works pretty well.
Block compression will be also pose a problem for the initial use-case and research direction I tried to follow – but more in that later!
What if we had many more channels?! PBR texture sets.
After a lengthy introduction, time to get back to the original purpose of my investigations – PBR texture sets for materials. How would SVD work there? My initial thinking was that if there are many more channels, some of them have to be correlated (as local areas will share physical properties – metal parts might have high specularity and gloss, while diffuse might be rough and more scratched). While such correlations might be only weak, there are many channels, and a lot of potential for also different, non-obvious correlations. Or correlations that are “accidental” and not related to the physical properties. 🙂
Since I don’t have access to any actual game assets anymore, and am not sure about copyright / licensing of many of the scenes included with the engines, I downloaded some texture set from cc0textures by Lennart Demes (such an awesome initiative!). Texture sets for materials there are a bit different than what I was used to in the games I worked on, but are more than enough for demonstration purpose.
I picked one set with some rocks/ground (on GoW, the programmers were joking that half of GoW disk was taken by rock textures, and at some point in the production it wasn’t that far off from true 🙂 ).
The texture set looks like this:

For the grayscale channels I took only single channels, and normals are represented using 3 channels, giving total of 9 channels.
The cool thing is – we don’t really have to “care” or understand what those color channels represent! We could even use 3 color channels to represent the “gray” textures, and the SVD would recognize it automatically (with some singular values ending up exactly zero) but I don’t want to present misleading/too optimistic data.
For visualization, I represented this texture set as horizontally stacked textures, but the first thing we are going to do is to first represent it as 2048 x 1365 x 9 array, and then for purpose of SVD as (2048 * 1365) x 9 one.
If we run the SVD on it (and then reshape it to w x h x 9), we get the following 9 decorrelated new “color”/image channels:

Alternatively, if we display it as 3 RGB images:

Immediately we can see that information contained in those decays very quickly, last four containing barely any information at all!
We can verify this looking at the plot of singular values:

As seen from the textures earlier, after 5 color channels, we get significant drop off of the information and start observing diminishing returns (“knee” of the cumulative curve).
Let’s have a look at how did SVD remap the input to the output channels and what kind of correlations it found.
In the following plot, I put abs(S.T) (using absolute value in most of my plots, as it’s easier to reason about existence of correlations, not their “direction”):

I marked two input textures – albedo and normals, and as they are a 3-channel representation of the some physical property and we can see how because of this correlation they contribute to very similar output color channels, almost like same “blocks”. We can also observe that for example the last two output features contribute to a little bit of AO, little bit of albedo, and a bit to one channel of normals – comprising some leftover residual error correction in all of the channels.
Now, if we were to preserve only some of the output channels (for data compression), what would be the reconstruction quality? Let’s start with the most “standard” metric, PSNR:
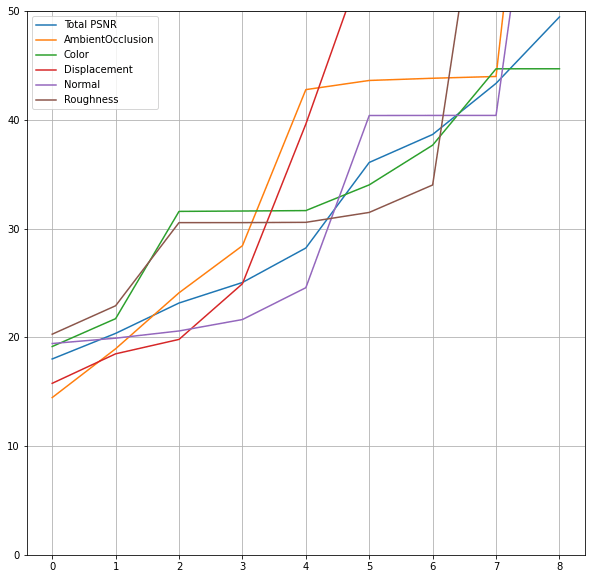
I skipped keeping of 9 channels in the plot, as for those we would expect “infinite” PSNR (minus floating point imprecisions / roundoff error).
So generally, for most of the channels, we can get above ~30dB with keeping only 5 data channels – which is what we intuitively expected from looking at the singular values. This is how reconstruction from keeping only those 5 channels looks like:

Main problems I can see is slight albedo discoloration (some rocks lose the desaturated rock scratches) and different frequency content on the last, roughness texture.
Going back to the PSNRs plots, we can see that they are different per channels and e.g. displacement becomes very high quickly, while the color and roughness stay pretty low… Can we “fix” those and increase the importance of e.g. color?
Input channel weighting / importance
I mentioned before that many ML applications would want to “standardize” the data before computing PCA / SVD and make sure range (as expressed by min/max or standard deviations) is the same to make sure we don’t bake in assumption of importance of any features as compared to the others in the analysis.
But what if we wanted to bake our desired importance / weighting into the decomposition? 🙂
Artists do this all the time manually by adjusting the resolutions of different sets of PBR textures to different resolutions; most 3D engine have some reasonable “defaults” there. We can use the same principles to guide our SVD and improve the reconstruction ratio. To do it, we would simply rescale the input channels (after the mean subtraction) by some weights that control the feature importance. For the demonstration, I will rescale the color map to be 200% as important, while reducing the importance of displacement to 75%.
This is how channel contributions and PSNR curves look like before/after:

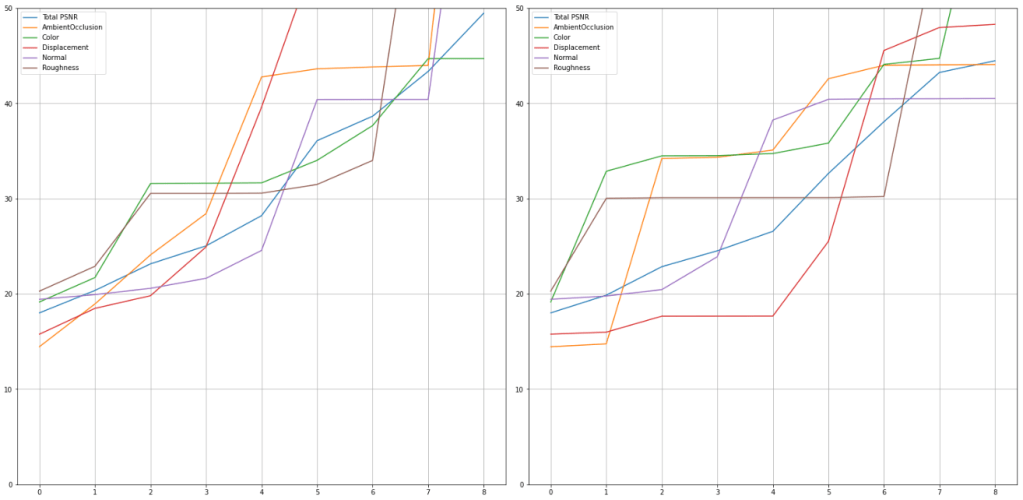
Such simple weighting directly improved some of the metrics we might care about. We had to “sacrifice” PSNR and reconstruction quality in different channels, but this can be a tuneable, conscious decision.
And finally, the visual results for materials reconstructed from just 5 components:

Other than some “perceptual” or artist-defined importance, I think that it could be also adjusted automatically – decreasing weight of channels that are reconstructed beyond diminishing returns, and increasing of the ones that get too high error. It could be some semi-interactive process, dynamically adjusting number of channels preserved and the weighting – an area for some potential future research / future work. 🙂
Dropping channels vs smaller channels
So far I have described “dropping channels” – this is really easy to get significant space savings (e.g. 5/9 == almost 50% savings with PSNR in the mid 30s), but isn’t it too aggressive? Maybe we can do the same thing as JPG and similar encoders do – just store the further components at smaller resolutions.
For the purpose of this post and just demonstration, I will do something really “crude” and naive – box filter and subsample (similar to mip-map generation), with nearest neighbor upsampling – we know we can do better, but it was simpler to implement and still demonstrates the point. 🙂
For demonstration I kept the 4 components at the original resolution, then 3 components at half resolution, and the final 2 components at quarter resolution. In total this gives us slightly smaller storage than before (7/16th), but the PSNRs are as follow: Average PSNR 36.96, AO 43.69, Color 41.08, Displacement 29.98. Normal 41.25, Roughness 35.13.
Not too bad for such naive downsampling and interpolation!
When downsampled, images looked +/- the same, so instead here is a zoom-in to just crops (as I expected to see some blocky artifacts):

With the exception of the height map which we have purposefully “downweighted” a lot, the reconstruction looks perceptually very good! Note that this ugly “ringing” and blocky look of it would be significantly better if even simple bilinear interpolation was used.
I’d add that we typically have also a third option – adjusting the quantization and the number of bits we encode each of our channels. This actually makes the most sense (because our channel value ranges get smaller and smaller and we know them directly from the proportions singular values), and is something I’d recommend playing with.
Runtime cost – conversion back to the original channel space
Before I conclude with the biggest limitation and potentially a “deal breaker” of the technique, a quick note on the runtime cost of such decomposition technique.
The decomposed/decorrelated color channels are computed with zero mean and unity standard deviation, so we would generally want to shift them by 0.5 and rescale so that they cover range [0, 1], instead of [-min, max]. Let’s call this a (de)quantization matrix M. So far we have matrices U (pixels x N), S (N x N diagonal), T (N x N, orthogonal), M (we could do N+1 x N to use “homogenous coordinates” and get translations for mean centering for free), input feature weight matrix / vector W, and vector with means A.
We can multiply all of those matrices (other than U which becomes our new image) offline and as a part of precomputation and using homogenous coordinates (N input features + ‘1’ constant in additional channel), we end up with a (N+1 x N) conversion matrix if keeping all channels, or (N x M+1) where M < N if dropping some channels. The full runtime application cost becomes a matrix multiply per pixel – or alternatively, a series of multiply-adds – each reconstructed feature becomes a weighted linear combination of the “compressed” / decorrelated features, so total cost per a single texture channel is M+1 madds.
This is very cheap to do on a GPU without any optimizations (maybe one could use “tensor cores” which are simply glorified mixed-precision matrix-multipliers?), but has a disadvantage that even if we are going to use a single channel (for example heightmap for raymarching or in a depth prepass), we still need to read all the input channels. If you have many passes or use-cases like this, this could elevate the required texture bandwidth significantly, but otherwise could be almost “free” (ALU is generally cheap, especially if doesn’t have any branching that would elevate the used register count).
Note however that it’s not all-or-nothing – if you want you could store some textures as before, and compress and reduce dimensionality of the other ones.
Caveats / limitations – BC texture compression
Time to reveal the reason why I haven’t followed up on this research direction earlier – I imagine that to many of you, it might have been obvious throughout the whole post. This approach is going to generally lose a lot of quality when being compressed with GPU block compression formats.
You remember how I described that the simplest BC formats do some local PCA and then just keep only single principal component? Now, if we purposefully decorrelated our color channels and there is no correlation anymore, such a fit and projection is going to be pretty bad! 😦
Now, it’s not that horrible – after all, we have found global decorrelation for the whole texture. Luckily, this doesn’t mean that there won’t be local (per block) one.
BC formats do this analysis per block (otherwise every image would end up as some form of “colored grayscale”) and there still might be potential for local correlations and not losing all the information with block compression. This is how our color channels to compress look like:

So generally, locally we see mostly flat regions, or combinations of two colors.
This is not any exhaustive test, proof, or analysis, just a single observation, but maybe it won’t be as bad as I thought when I abandoned this idea for a while – but it’s a future research direction! If you have any thoughts, experiments, or would like to brainstorm, let me know in the comments or contact me. 🙂
Summary
In this post we went through quite a few different concepts:
- Idea of “decorrelating” color channels to maximize information contained in them and remove the redundancy,
- One alternative possible way how to think about images or image patches for linear algebra applications – as 2D matrices, not 3D tensors,
- Very brief introduction to use of SVD for computing “optimal” decorrelated channel decompositions (SVD for PCA-like dimensionality reduction),
- Relationship between the least-squares line fitting and SVD/PCA (they are not the same!),
- Demonstration of SVD decomposition on a 2-channel, “toy” problem,
- Relationship of such decomposition to Block Compression formats used on GPUs,
- Reducing the resolution/quantization/fully dropping “less significant” decorrelated color channels,
- Comparison of efficacy of SVD as compared to YUV color space conversion that is commonly used for image transmission and compression,
- Potential application of dimensionality reduction for compressing the full PBR texture sets,
- And finally, caveats / limitations that come with it.
I hope you found this post at least somewhat interesting / inspiring and encouraging some further experiments with using the multi-channel texture / material cross-channel correlation.
While the scheme I explored here has some limitations for practical GPU applications (compatibility with BC formats), I hope I was able to convince you that we might be leaving some compression/storage benefits unexplored, and it’s worth investigating image channel relationships for dimensionality reduction and potentially some smarter compression schemes.
As a final remark I’ll add that applicability of this technique depends highly on the texture set itself, and how quickly the singular values decay. I have definitely seen more correlated texture sets than the example, but it’s also possible that on some inputs the correlation and technique efficacy might be worse – all depends on your data. But you don’t have to make a decision whether to use it or how many channels to keep manually – by analyzing the singular values as well as the PSNR itself it can be easily deducted from data and the decision automated.
The post comes with three colabs: Part 1 – toy problem, Part 2 – Kodak images, Part 3 – PBR materials which hopefully will encourage verification / reproduction / exploration.
Thanks for reading!

This is great work!
A quick question (and forgive me if already answered but I have only diagonally read the post): Did you push the reconstructed texture set back into the shader for visual assessment and comparison? Normals and displacement might suffer, although you would not see a drastic difference from “simply” looking at the textures. I know that you use PSNR but, it is not always the appropriate metric!
No, I didn’t test that. Your point is very valid and a real concern that I have not tested. I mention that one can increase the importance of certain channel (and normals are a perfect example of a channel that we typically care about a lot, since it shows up in sharp specular reflections), so if there are artifacts they could be mitigated.
I also agree that PSNR is not the best metric, and it is a “convenient” for this use-case since SVD optimizes for L2 (the same as PSNR). 🙂 So I agree that YMMV on a more “perceptual” one. (wish there was some standardized way to test normals, angle deviation after normalization maybe?)
It is indeed tricky! I was wondering if there was a case to weight the PSNR with concavity/convexity information or an edge detection mask and attribute more points where the mask is the most intense because it might be where the most important information is located: the HVS is extremely good at detecting contrast changes.
I’ve used a similar approach for neural networks that tend to produce soft and desaturated image when using L2 loss. I defined a loss functions for brightness and saturation (Simple MSE on the Y and the S value of HSV), color (MSE((RGB1 – RGB2) / MAX([RGB1, RGB2]))) and sharpness (simple 3×3 edge detector) and eyeballed coefficients for the final loss. Even equal weight work quite well visually.
The cause of sharpness loss was nicely analyzed in a recent paper “Fourier Features Let Networks Learn High Frequency Functions in Low Dimensional Domains”, before that it was not uncommon to use something similar to what you describe (image gradients, Laplace pyramids etc).
“Advantage” of the approach I described here (apart from unquestionable ones like closed form and single matmul evaluation) is that it ignores spatial relationships – has no degreees of freedom for blurring. The only blurring can come from downsampling of the compressed textures, but from my experiments it’s unlikely to produce softness, more of visible artifacts.
I took a similar approach in Relightable Images here:
http://vcg.isti.cnr.it/Publications/2018/PCS18/
My first approach was to apply the same technique you described to the coefficients of the PTM planes (or HSH), in the end I used directly the hundreds of images, due to the linearity of the rendering algorithm. (unlinke PBR…)
I wonder if it’s possible to not only compress the textures but also change the rendering formulas and (as suggested by kelsolaar) measure the difference int the final image.
Hi Federico, thanks for the comment. I finally had a chance to read your paper, thank you for sharing. One thing I was wondering re proposed compression scheme is why you decompose to YCbCr instead of flattening channels and letting the PCA discover those relationships (more optimal in L2 sense) – is it to control the chroma error?
Pingback: Compressing PBR material texture sets with sparsity and k-SVD dictionary learning | Bart Wronski
Pingback: Neural material (de)compression – data-driven nonlinear dimensionality reduction | Bart Wronski
Pingback: Study of smoothing filters – Savitzky-Golay filters | Bart Wronski
Pingback: Insider guide to tech interviews | Bart Wronski
Pingback: Light transport matrices, SVD, spectral analysis, and matrix completion | Bart Wronski
Pingback: Removing blur from images – deconvolution and using optimized simple filters | Bart Wronski
Pingback: Programming PCA From Scratch In C++ « The blog at the bottom of the sea
Pingback: Calculating SVD and PCA in C++ « The blog at the bottom of the sea
Legacy/typical Non-Constant Luminance YUV conversion has a correlation problem that in SDR was ignored but typical +8% but in HDR 11~44% bigger size;
So one way is to convert RGB to Constant Luminance-YUV or just use YCoCg