
Let’s try a new format – “shorts”; small blog posts where I elaborate on ideas that I’d discuss at my twitter, but they either come back over and over, or the short form doesn’t convey all the nuances.

I often see advice about avoiding “if” statements in the code (especially GPU shaders) at all costs. The worst of all is when this happens in glsl and programmers replace some simple if statements with (subjectively) horrible step instruction which IMO completely destroys all readability, or even worse – sequences of mixes, maxes, clips and extra ALU.
After all, those ifs are branches, and branches are bad, right?
TLDR: No, definitely not – on all accounts.
Why do programmers want to avoid branches?
Let’s first address why programmers would like to avoid branches. There are some good reasons for that.
Scalar CPU
On the CPU, “branches” in a non-SIMD code might seem “innocent”, it’s just a conditional jump to some other code. Instead of executing an instruction a next address, we jump to instruction b at some other address. Unfortunately, there are many complicated things going on under the hood: All modern CPUs are heavily pipelined, superscalar, and out-of order.
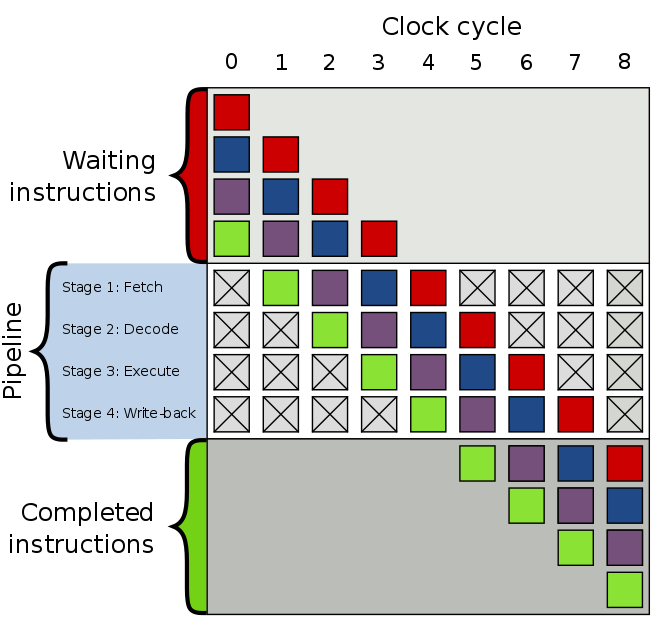
To extract maximum efficiency, they use a model of speculative execution – a CPU “gambles” and “guesses” results of a branch ahead of time, not knowing if it will be taken or not, and starts executing those instructions. If it’s right – great! However if it’s not, then the CPU needs to stall, cancel all the guesses, go back to the branch, and execute the other instructions. Oops.
Luckily, CPUs are usually very good at this “guessing” (they actually analyze past branch patterns and take them into account!). On the other hand, without going into too much detail – each branch consumes some of the branch predictor unit resources. One extra branch on some short, innocent code can make results of the branch prediction worse, and slow down other code (where branch predictor might be necessary for good performance!).
SIMD and the GPU
When considering SIMD or the GPU, the situation is even worse.
Simplifying – single program and same instruction stream executes on multiple “lanes” of the same data, processing 4/8/16/32/64 elements at the same time.
If you want to take a branch when some of the elements take one path, some another one, you have two main options: either abandon vectorization and scalarize code (very bad option; usually means that it’s not worth vectorizing given piece of code), or execute both code paths – first the first one, store the results somewhere, execute the second one, and “combine” the results.

This is a general (over)simplification, and example GPUs have dedicated hardware to help do it efficiently and without wasting resources (hardware execution masks etc), but generally means extra cost of managing those masks, storing results somewhere, double execution costs and finally – branches can serve as barriers, preventing some latency hiding (see my old blog post on it).
Combined
Given those two, it might seem that avoiding branches seems reasonable, and the common advice of avoiding ifs makes sense. But whether it makes sense to avoid branch or not is more complicated (more on it later), and the second one (whether an if is a branch) is not the case.
Are if statements branches?
Let’s clear the worst misconception.
When you write an “if” in your code, the compiler won’t necessarily generate a branch with a jump.
I will focus now on CPUs, mostly because how easy it is to test it with Matt Godbolt’s amazing compiler explorer. 🙂 (Plus how there are two mainstream architectures, unlike many different shader ISAs)
Let’s have a look at the following simple integer function.
int is_this_a_branch(int v, int w) {
if (v < 10) {
return v + w;
}
else {
return 2 * v - 2 * w;
}
}
I tested it with 3 x64 compilers (GCC x64 trunk, Clang x64 trunk, MSVC 19.28) and one ARM (armv8-a clang), and only MSVC generates an actual branch there.
clang
mov eax, edi
sub eax, esi
add esi, edi
add eax, eax
cmp edi, 10
cmovl eax, esi
ret
gcc
mov eax, edi
lea edx, [rdi+rsi]
sub eax, esi
add eax, eax
cmp edi, 9
cmovle eax, edx
ret
msvc
cmp ecx, 10
jge SHORT $LN2@is_this_a_ BRANCH!!!
BRANCH!
lea eax, DWORD PTR [rcx+rdx]
ret 0
$LN2@is_this_a_:
sub ecx, edx
lea eax, DWORD PTR [rcx+rcx]
ret 0
arm clang
sub w9, w0, w1
add w8, w1, w0
lsl w9, w9, #1
cmp w0, #10 // =10
csel w0, w8, w9, ltWhen using floats:
float is_this_a_branch2(float v, float w) {
if (v < 10.0f) {
return v + w;
}
else {
return 2.0f * v - 2.0f * w;
}
}
Now 2 out of 4 compilers generate a branch:
clang
movaps xmm2, xmm0
addss xmm2, xmm1
movaps xmm3, xmm0
addss xmm3, xmm0
addss xmm1, xmm1
cmpltss xmm0, dword ptr [rip + .LCPI1_0]
subss xmm3, xmm1
andps xmm2, xmm0
andnps xmm0, xmm3
orps xmm0, xmm2
ret
gcc
movss xmm2, DWORD PTR .LC0[rip]
comiss xmm2, xmm0
jbe .L10 BRANCH!!!
addss xmm0, xmm1
ret
.L10:
addss xmm1, xmm1
addss xmm0, xmm0
subss xmm0, xmm1
ret
msvc
movss xmm2, DWORD PTR __real@41200000
comiss xmm2, xmm0
jbe SHORT $LN2@is_this_a_ BRANCH!!!
addss xmm0, xmm1
ret 0
$LN2@is_this_a_:
addss xmm0, xmm0
addss xmm1, xmm1
subss xmm0, xmm1
ret 0
arm clang
fadd s2, s0, s1
fadd s3, s0, s0
fadd s1, s1, s1
fmov s4, #10.00000000
fsub s1, s3, s1
fcmp s0, s4
fcsel s0, s2, s1, mi
retWhat are those conditionals and selects?
This is basically CPUs’ and compilers’ way of “serializing” both code paths. If it considers overhead of a branch larger than the amount of work it can save, it makes sense to compute both code paths, and use a single instruction to select which one is the actual result.
This obviously “depends” on the use case and whether it is even “legal” for a compiler to do such a transformation (like “side effects”; or if a compiler executed some reads of memory, it could be unsafe and lead to segmentation fault).
Does writing ternary conditional help avoid branches?
No.
This is a common advice, but it’s generally not true. If you look at the above example rewritten slightly:
float is_this_a_branch3(float v, float w) {
return v < 10.0f ? (v + w) : (2.0f * v - 2.0f * w);
}
The generated code is identical (!).
It might be possible (?) that some compilers do generate branchless code for like this, but giving this as a general advice makes no sense. Whether you write an actual if, or a ternary expression, it’s still a high level if statement, just expressed differently.
What about the GPU?
On the GPU, it’s the same; the compiler will generate conditional selects when appropriate.
I used Tim Jones Shader Playground and AMD ISA (mostly because I know it relatively better than the others), and the unfortunate step function:
#version 460
layout (location = 0) out vec4 fragColor;
layout (location = 0) in float inColor;
void main()
{
#if 1
fragColor = vec4(step(1.0, inColor));
#else
float x;
if (inColor < 1.0)
x = 1.0;
else
x = 0.0;
fragColor = vec4(x);
#endif
}
See for yourself, both versions generate identical assembly:
s_mov_b32 m0, s3
s_nop 0x0000
v_interp_p1_f32 v0, v0, attr0.x
v_interp_p2_f32 v0, v1, attr0.x
v_cmp_gt_f32 vcc, 1.0, v0
v_cndmask_b32 v0, 1.0, 0, vcc
v_cvt_pkrtz_f16_f32 v0, v0, v0
exp mrt0, v0, v0, v0, v0 done compr vmWhen using fastmath and not obeying strict IEEE float specification (which is standard for compiling shaders for real time graphics), compilers can even generate other instructions like min or max from your if statements. But YMMV and be sure to check the assembly.
So generally – using “step” just to avoid if statements is pointless.
If you like it for your coding style, then it’s obviously up to you, use as much as you like just for this reason. But please consider programmers who don’t have as much shader or GLSL experience and will be always puzzled by it. 🙂
Are branches always to be avoided?
No.
This is way beyond my aimed “short” format, but branches are not necessarily “bad”.
They can be actually an awesome optimization, even on the GPU!
If you start to use a lot of conditionals
Lots of advice on how branches are bad and have to be avoided comes from a prehistoric era of old CPUs and GPUs or old compilers; an advice that is passed without re(verifying) – which is understandable, I am not re-checking my whole knowledge or intuition every few months either. 🙂
But the CPU/GPU/compiler architects improved designs significantly and adapted them to general, highly branchy code, and whether there is a penalty or not depends on way too many details to list or give advice.
Rule of thumb: if a branch is generally coherent, it makes sense to use it when it allows to save on memory bandwidth or cache utilization. On GPUs it is usually worth adding branches if you can avoid texture fetches this way with a high probability and coherence. And it’s usually better to have some conditional masks and selects around simple/short sequences of arithmetic operations.
Final advice
- Don’t assume that an “if” statement will generate a branch. For most of simple “if” statements, the compiler can and will use conditional selects. Compilers can do many powerful transformations, sometimes ones that you wouldn’t even consider.
- Unless writing performance critical code, optimize for code readability. Don’t use obscure instructions and weird arithmetic.
- If you care for performance of a hot section, always read the resulting assembly and verify what is the compiler output.
- Don’t assume that a branch is bad. Profile your code – both in microbenchmarks, as well as in surrounding context (effects on cache, memory bandwidth, and branch predictor).

With /O2 optimization, msvc no longer branches when the formula itself determines which values to return:
return (v < 10.0f)*(v + w) + (v >= 10.0f)*(2.0f * v – 2.0f * w);
there are no jump instructions generated, but isn’t “cmovl” a (kind of) branch in and of itself?
Because it like the code was rewritten as:
int is_this_a_branch(int v, int w) {
int eax = v;
eax = eax – w;
w = w + v;
eax = eax + eax;
if (v < 10) {
eax = w;
}
return eax;
}
No, conditional moves are not branches – both in terms of actual code execution in the processing unit (no branch mask, no branch predictor), as well as conceptually. Taking the Turing machine concept, branch is something that would make the the tape head go to some other location, kind of conditional jump that changes what and how is being executed. Conditional move is just like conditional computation that doesn’t change it.
This way you can use cmovs easily in a SIMD or a GPU context.
> if a branch is generally coherent
What does ‘coherent’ mean in this context?
Coherent in terms of branches on a GPU means that all vector threads take similar path, or a “regular” path. For example if you have 30 / 32 threads take same path of the branch, it’s very coherent; or if 16 take it, but the first 16, not like 0 1 1 0 1 …
The second type of coherency matters due to the way some lower level execution units like a texture sampler are organized (for example on AMD “fusing” memory access of 4 adjacent elements into a single memory transaction so having 4 elements run and 4 next take other path is much better than 0 1 1 1 0 1 0 0)
Splendid. Thank you.
Pingback: Insider guide to tech interviews | Bart Wronski