
Intro
This post will cover challenges and aspects of production to consider when creating new rendering / graphics techniques and algorithms – especially in the context of applied research for real time rendering. I will base this on my personal experiences, working on Witcher 2, Assassin’s Creed 4: Black Flag, Far Cry 4, and God of War.
Many of those challenges are easily ignored – they are real problems in production, but not necessarily there only if you only read about those techniques, or if you work on pure research, writing papers, or create tech demos.
I have seen statements like “why is this brilliant research technique X not used in production?” both from gamers, but also from my colleagues with academic background. And there are always some good reasons!
The post is also inspired by my joke tweet from a while ago about appearing smart and mature as a graphics programmer by “dismissing” most of the rendering techniques – that they are not going to work on foliage. 🙂 And yes, I will come back to vegetation rendering a few times in this post.
I tend to think of this topic as well when I hear discussions about how “photogrammetry, raytracing, neural rendering, [insert any other new how topic] will be a universal answer to rendering and replace everything!”. Spoiler alert: not gonna happen (soon).
Target audience
Target audience of my post are:
- Students in computer graphics and applied researchers,
- Rendering engineers, especially ones earlier in their career – who haven’t built their intuition yet,
- Tech artists and art leads / producers,
- Technical directors and decision makers without background in graphics,
- Hardware engineers and architects working on anything GPU or graphics related (and curious what makes it complicated to use new HW features),
- People who are excited and care about game graphics (or real time graphics in general) and would like to understand a bit “how sausages are made”. Some concepts might be too technical and too much jargon, but then feel free to skip those.
Note that I didn’t place “pure” academic researchers in the above list – as I don’t think that pure research should be considering too many obstacles. Role of the fundamental research is inspiration and creating theory that can be later productionized by people who are experts in productionization.
But if you are a pure researcher and somehow got here, I’ll be happy if you’re interested in what kinds of problems might be on the long way from idea or paper to a product (and why most new genuinely good research will never find its place in products).
How to interpret the guide
Very important note – none of the “obstacles” I am going to describe are deal breakers.
Far from it – most successful tech that became state of the art violates many of those constraints! It simply means that those are challenges that will need to be overcome in some way – manual workarounds, feature exclusivity, ignoring the problems, or applying them only in specific cases.
I am going to describe first the use-cases – potential uses of the technology and how those impact potential requirements and constraints.
Use case
The categories of “use cases” deserve some explanation and description of “severity” of their constraints.
Tech demo
Tech demo is the easiest category. If your whole product is a demonstration of a given technique (whether for benchmarking, showing off some new research, artistic demoscene), most of the considerations go away.
You can actually retrofit everything: from the demo concept, art itself, camera trajectory to show off the technology the best and avoid any problems.
The main considerations will be around performance (a choppy tech demo can be seen as a tech failure) and working very closely with artists able to show it off.
The rest? Hack away, write one-off code – just don’t have expectations that turning a tech demo into a production ready feature is simple or easy (it’s more like the 99% of work remaining).
Special level / one-off
The next level “up” in the difficulty is creating some special features that are one-off. It can be some visual special effect happening in a single scene, game intro, or a single level that is different from the other ones. In this case, a feature doesn’t need to be very “robust”, and often replaces many others.
An example could be lighting in the jungle levels in Assassin’s Creed 4: Black Flag that I worked on.

Jungles were “cut off” from the rest of the open world by special streaming corridors and we completely replaced the whole lighting in them! Instead of relying on tree shadow maps and global lighting, we created fake “caustics” that looked much softer and played very nicely with our volumetric lighting / atmospherics system. They not only looked better, but also were much faster – obviously worked only because of those special conditions.
Cinematics
A slightly more demanding type of feature is cinematic-only one. Cinematics are a bit different as they can be very strictly controlled by cinematic artists and most of their aspects like lighting, character placement, or animations are faked – just like in regular cinema! Cinematics often feature fast camera cuts (useful to hide any transitions/popping) and have more computational budget due to more predictable nature (and even in 60fps console games rendered in 30fps).

Regular rendering feature
“Regular” features – lighting, particles, geometry rendering – are the hardest category. They need to be either very easy to implement (most of the obstacles / problems solved easily), provide huge benefits surpassing state of the art by far to facilitate the adoption pain, or have some very excited team pushing for it (never underestimate the drive of engineers or artists that really want to see something happen!).
Most of my post will focus on those.
Key / differentiating feature
Paradoxically, if something is a key or differentiating feature, this can alleviate many of the difficulties. Let’s take VR – there stereo, performance (low latency), and perfect AA with no smudging (so rather forget about TAA), are THE features and absolutely core to the experience. This means that you can completely ignore for example rendering foliage or some animations that would look uncannily – as being immersed and the VR experience of being there are much more important!
Feature compatibility
Let’s have a look at compatibility of a newly developed feature with some other common “features” (the distinction between “features”, and the next large section “pipeline” is fuzzy).
Features are not the most important of challenges – arguably the category I’m going to cover at the end (the “process”) is. But those are fun and easy to look at!
Dense geometry
Dense geometry like foliage – a “feature” that inspired this post – is an enemy of most rendering algorithms.
The main problem is that with very dense geometry (lots of overlapping and small triangles), many “optimizations” and assumptions become impossible.
Early Z and occlusion culling? Very hard.
Decoupling surfaces from volumes? Very hard.
Storing information per unique surface parametrization? Close to impossible.
Amount of vertices to animate and pixels to shade? Huge, shaders need simplification!

Dense geometry through which you can see (like grass blades) is incompatible with many techniques, for example lightmapping (storing a precomputed lighting per every grass blade texel would be very costly).
If a game has a tree here and there or is placed in a city, this might not be a problem. But for any “natural” environment, a big chunk of the productionization of any feature is going to be combining it to coexist well with foliage.
Alpha testing
Alpha testing is an extension of the above, as it disables even more hardware features / optimizations.
Alpha testing is a technique, when a pixel evaluates “alpha” value from a texture or pixel shader computations, and based on some fixed threshold, doesn’t render/write it.
It is much faster than alpha blending, but for example disables early z writes (early z tests are ok), and requires raytracing hit shaders and reading a texture to decide if a texel was opaque or not.
It also makes antialiasing very challenging (forget about regular MSAA, you have to emulate alpha to coverage…).
For a description and great visual explanation of some problems, see this blog post of Ben Golus.
Animation – skeletal
Most animators work with “skeletal animations”. Creating rigs, skinning meshes, animating skeletons. When you create a new technique for rendering meshes that relies on some heavy precomputations, would animators be able to “deform” it? Would they be able to plug it into a complicated animation blending system? How does it fit in their workflow?
Note that it can also mean rigid deformations, like a rotating wheel – it’s much cheaper to render complicated objects as a skinned whole, than splitting them.
And animation is a must, cannot be an afterthought in any commercial project.

Animation – procedural and non-rigid
The next category of animations are “procedural” and non-rigid. Procedural animations are useful for any animation that is “endless”, relatively simple, and shouldn’t loop too visibly. The most common example is leaf shimmer and branch movement.
See this video of middleware Speedtree movement – all movement there is described by some mathematical formulas, not animated “by hand” and looks fantastic and plausible.
A good rendering technique that is applicable on elements like foliage (again!) needs to support the option of displacing it in any arbitrary fashion from simple shimmer to large bends – otherwise the world will look “dead”.
Non-rigid animation, modifying vertex positions, or even streaming whole vertex buffers causes headaches for the raytracing – as it requires readjusting the spatial acceleration structures (essential for RT) every single frame, which is impractical.
Animation – textures
Yet another type of animation is animating textures on surfaces of objects. This is not just for emulating neons or TVs, but also for example raindrops and rain ripples. Technical and FX artists have lots of amazing tricks there, from just sliding and scaling UVs, having flowmaps, to directly animating “flipbook” textures.

Dynamic viewpoint
Many techniques work well assuming a relatively fixed camera viewpoint. From artists tricks and hacks, to techniques like impostor rendering.
Some rendering acceleration techniques optimize for a semi-constrained view (like Project Seurat that my colleagues worked on). Degrees of camera freedom are something to be considered when adapting any technique. A billboard-based tree can look ok from a distance, but if you get closer, or can see the scene from a higher viewpoint, it will break completely.
Also – think of early photogrammetry that was capturing the specular reflections as textures, which look absolutely wrong when you change the viewpoint even slightly.
Dynamic lighting
How dynamic is the lighting? Is there a dynamic time of day? Weather system? Can the user turn on/off lights? Do special effects cast lights? Are there dynamic shadow casting objects?
The answer is going to be “yes” to many of those questions for most of the contemporary real-time rendering products like games; especially with a tendency of creating larger, living worlds.
This doesn’t necessarily preclude precomputed/baked solutions (like our precomputed GI solution for AC4 that supported dynamic time of day!) but needs extra considerations.
There are still many new publications coming out that describe new approaches and solutions to those problems (combining precomputations of the light transport, and the dynamic lighting).
Shadows
Shadows, another never ending topic and an unsolved problem. Most games still use a mixture of precomputed shadows and shadow maps, some start to experiment with raytraced shadows.
Anytime you want to insert a new type of object to be rendered, you need to consider: is it going to be able to receive shadows from other objects? Is it going to cast shadows on other objects?
For particles or volumetrics, the answer might not be easy (as partial transmittance is not supported by shadow maps), but also “simple” techniques like mesh tessellation or parallax occlusion mapping are going to create a mismatch between shadow caster and the receiver, potentially causing shadowing artifacts!

Dynamic environment
Finally, if the environment can be dynamic (through game story mandated changes, destruction, or in the extreme case through user content creation), any techniques relying on offline precomputation become challenging.
On God of War the Caldera Lake and the bridge, moving levels of water and bridge rotations were one of the biggest concerns throughout the whole production from the perspective of lighting / global illumination systems that rely on precomputations. There was no “general” solution, it all relied on manual work and streaming / managing the loaded data…

Transparents and particles
Finally, there are transparent objects and particles – a very special and different category than anything else.
They don’t write depth or motion vectors (more on it later), require back-to-front sorting, need many evaluations of costly computations and texture samplers per final output piels, usually are lit in a simpler way, need special handling of shadows… They are also very expensive due to overdraw – a single output pixel can be many evaluations of alpha blended particles’ pixel shaders.
Person-years of work (on most projects I worked on there were N dedicated FX artists and at least one dedicated FX and particle rendering engineer) that cannot be just discarded or ignored by a newly introduced technique.
Pipeline compatibility
The above were some product features and requirements to consider. But what about some deeper, more low-level implications? Rendering of a single frame requires tens of discrete passes that are designed to work with each other, tens of intermediate outputs and buffers. Let’s look at parts of the rendering pipeline to consider.
Depth testing and writing
I mentioned above some challenges with alpha testing, alpha blending, sorting, and particles. But it gets even more challenging when you realize that many features require precise Z buffer values in the depth buffer for every object!
That creamy depth of field effect and many other camera effects? Most require a depth buffer. Old school depth fog? Required depth buffer!

Ok, this seems like a deal breaker, as we know that alpha blended objects don’t write those and there cannot be a single depth value corresponding to them… But games are a mastery of smoke and mirrors and faking. 🙂 If you really care you can create depth proxies by hand, sort and reorder some things manually, alpha blend depth (wrong but can look “ok”), tweak depth of field until artifacts are not distracting… Lots of manual work and puzzles “which compromise is less bad”!
Motion vectors
A related pipeline component is writing of the motion vectors. While depth is essential for many mentioned depth based effects, proper occlusions, screen-sapce refractions, fog etc, the motion vectors are used for “only” two things: motion blur and temporal antialiasing (see below).
Motion blur seems like “just an effect”, but having small amounts of it is essential to reduce the “strobing” effect and generally cheap feel (see movie 24fps half shutter motion blur).
(Some bragging / Christmas time nostalgia: thinking about motion blur made me feel nostalgic – motion blur was the first feature I got interviewed about by the press – I still feel the pride the 23 year old me living in Eastern Europe and that didn’t even finish the college felt!)
Producing accurate motion vectors is not trivial – for every pixel, you need to estimate where this part of the object was in the previous frame. This can mean re-computing some animation data again, storing it for the previous frame (extra used memory), or can be too difficult / impossible (dealing with occlusions, shadows, or texture animations).
On AC4 we have implemented it for almost everything – with an exception of the ocean and ignored the TAA and motion blur problems on it…
Temporal antialiasing
Temporal antialiasing… one of the biggest achievements of the rendering engines in the last few years, but also one of the biggest sources of problems and artifacts. Not going to discuss here if there are alternatives to it or if it’s a good idea or not, but it’s here to stay for a while – not just for the antialiasing, but also temporal distribution of samples in Monte Carlo techniques, supersampling, stochastic rendering, and allowing for slow things to become possible or higher quality in real-time.
It can be a problem for many new rendering techniques – not only because of the need for pretty good motion vectors, but also its nature can lead to some smearing artifacts, or even cancel out visual effects like sparkly snow (glints, sparkles, muzzle flash etc).

Deferred shading / lighting
Majority of the engines use deferred shading (yes, there are many exceptions and they look and perform fantastic). It has many desirable properties and “lifts” / decouples parts of the rendering, simplifies things like decals, can provide a sweet reduction of the overdraw…
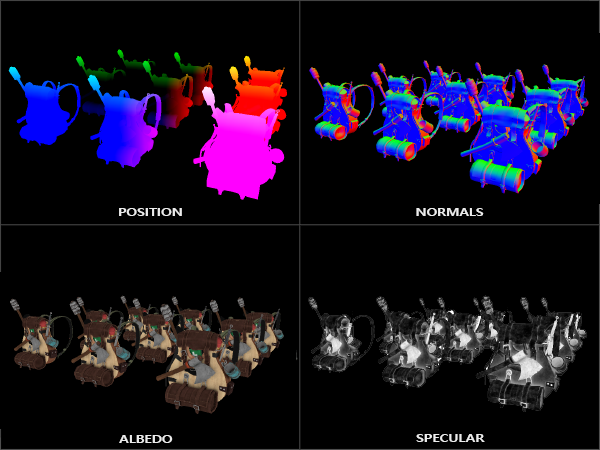
But having a “bottleneck” in form of the GBuffer and lighting not having access to any other data can be very limiting.
New shading model? New look-up table? New data precomputed / prebaked and stored in vertices or textures? Need to squeeze those into GBuffer!
Modern GPUs handle branching and divergence with ease (provided there is “some” coherency), but it can complicate the pipeline and lead to “exclusive” features.
For example on God of War you couldn’t use subsurface scattering at the same time as the cloth/retroreflective specular model due to them (re)using same slots in the GBuffer. The GBuffer itself was very memory heavy anyway and there were many more mutually exclusive features – I had many possible combinations written out in my notebook (IIRC there were 6 bits just for encoding the material type + its features) and “negotiating” those compromises between different artists who all had different uses and needs.
Any new feature meant cutting out something else, or further compromises…
Camera cuts / no camera cuts
In most cinematics, there are heavy camera cuts all the time to show different characters, different perspectives of the scene, or maybe action happening in parallel. This is a tool widely used in all kinds cinema (maybe except for Dogme 95 or Birdman 😉 ), and if a cinematic artist wants to use it, it needs to be supported.
But what happens when the camera cuts with all the per-pixel temporal accumulation history for TAA/temporal supersampling? How about all the texture streaming that suddenly sees a completely new view? View-dependent amortized rendering like shadowmap caching? All solvable, but also a lot of work, or might introduce unacceptable delay / popping / prohibitive cost of the new frame. A colleague of mine also noted that this is a problem for physics or animations – often when the camera cuts and animators adjusted some positions, you see physical objects “settling in”, for example a necklace move on a character. Another immersion breaker that requires another series of custom “hacks”.
Conversely, lack of camera cuts (like in God of War) is also difficult, especially for cinematics lighting, good animations, transitions etc. In any case – both need to be solved/accounted for. Even worth adding a flag “camera was cut” in the renderer.
Frustum culling
Games generally don’t render what you don’t see in the camera frustum – which is obviously desirable, as why would you waste cycles on it?

Now, it gets more complicated! Why would you animate objects that are not visible? Not doing so can save a lot of CPU time.
However things being visible in the main view is only part of the story – there are reflections, shadows… I cannot count in how many games I have seen the shadows of the off-screen characters in the “T-pose” (default pose when a character is not animated). Raytracing that can “touch” any objects poses a new challenge here!
Occlusion culling
Occlusion culling is the next step after frustum culling. You don’t want to render things outside of the camera? Sure. But if in front of the camera there is a huge building, you also don’t want to render the whole city behind it!

Robust occlusion culling (together with the LOD, streaming etc. below) is in many ways an unsolved problem – all existing solutions require compromises, precomputation, or extremely complex pipelines.
In a way an occlusion culling system is a new rendering feature that has to go through all the steps that I list in this post! 🙂 But given its complexity and general fragility of many solutions – yet another aspect to consider, we don’t want to make it even more difficult.
Level of detail
Any technique that requires some computational budget to render and memory usage needs to “scale” properly with distance. When the rendered object is 100m away and occupies a few pixels, you don’t want it to eat 100MB of memory or its rendering/update take even a millisecond.
Enter “level of detail” – simplified representation of objects, meshes, textures (ok, this one is automatic in form of mip-mapping, but you still need to stream those properly and separately), computations.

Unfortunately while the level of detail for meshes or textures is relatively straightforward (though in open world games it is not enough and gets replaced by custom long-distance rendering tech), it’s often hard to solve it for other effects.
How should the global illumination scale with distance? Volumetric effects? Lighting? Particles?
All hard problems that are often solved in very custom ways, through faking, hacking, and manual labor of artists…
Loading, LOD switching and streaming
Level of detail needs to be streamed. Ok, an object far away takes a few pixels on the screen, we can use just tens of vertices and maybe no textures at all – in total maybe a few kilobytes, all good. But then the camera starts to move closer, and we need to load the material, textures, meshes… All of this needs systems and solutions coded up. What happens when the camera just teleports? Streaming system needs to handle it.
Furthermore, switching between those LODs has to be as seamless as possible. Most visual glitches in games with some textures missing / blurry, things flickering, popping, appearing are caused by the streaming, loading, and the LOD switching systems!
Open world
I put the “open world” as a separate item, but it’s a collection of many constraints and requirements that together is different in a qualitative way – it’s not just a robust streaming system, but everything needs to be designed for streaming in open world games. It’s not just good culling – but a great culling system working with AI, animations and many other systems. Open world and large scale rendering is a huge pipeline constraint on almost everything, and has to be considered as such.
When I joined the AC4 team at Ubisoft and saw all the “open world” tech for streaming, long distance rendering and similar, or the long range shadows elements for Far Cry, I was amazed with how specialized (and smart) work was needed to fit those on consoles.
Budget
Finally, the budget… I’ll tackle the “production” budget below, but hope this one is self-explanatory. If a new technique needs some memory or CPU/GPU cycles, they need to be allocated.
One common misconception is that 30ms is “real time technique”. It can be, but only if this is literally the only thing rendered, and only in a 30fps game.
For VR you might have to deal with budgets of sub 10ms to render 2 eye views for the whole frame! This means that a lighting technique that costs 1ms might already way be too expensive!
Similarly with RAM memory – all the costs need to be considered holistically and usually games already use all available memory. Thus any new component means sacrificing something else. Is a feature X worth reducing texture streaming budget and risking texture streaming glitches?
Finally, another “silent” budget is disk space. This isn’t discussed very often, but with modern video game pipelines we are at a point where games hardly fit on Blu Ray disks (it was a bigger challenge on God of War than fitting in memory or the performance!).
Similarly, patches that take 30GBs – it’s kind of ridiculous and usually a sign of an asset packaging system that didn’t consider patching properly… But anyway, a new precomputed GI solution that uses “only” maybe 50MB per level chunk “suddenly” scales to 15GB on disk for the whole 30h game and that most likely will not be acceptable!
The process
While I left the process for the end (as might be least interesting to some audience), challenges listed here are the most important.
Many “alternative” approaches to rendering are already practical in many ways (like signed distance fields), but the lack of tooling, pipelines, and production experience is a complete blocker for all but for special examples that for example rely on user created content (see brilliant Dreams or Claybook).
Artistic control
It’s easy to get excited with some amazing results of procedural rendering (been there for many decades), photogrammetry, or generally 3D content capture and re-rendering – the results look like eye-candy and might seem like removing a huge chunk of production costs.
However artists need full control and agency in the process of content making.
Capturing a chair with a neural implicit representation is easy, but can you change the color of the seat, make some part of it longer, and maybe change the paint to varnished? Or when the art director decides that they want a baroque style chair, are you going to look for one?
Generally most artists are skeptical of procedural generation and capture (other than to quickly fill huge areas of levels that are not important to them) as they don’t have those controls.
On Assassin’s Creed 4, one of my teammates worked on procedural sky rendering (it was a collaboration with some other teams, and also IIRC had an evaluation of some middleware). It looked amazing, but the art director (who was also a professional painter) was not able to get exactly the look he wanted, and we went with very old-school, static (but pretty!) skyboxes.

Tools
Every tool or technique that is creative / artistic, needs tooling to express the control, place it on levels, allow for interaction. “Tools” can be anything from editing CSV files to dedicated WYSIWYG full editors.
Even the simplest new techniques need some tools / control (even if it is as simple as on/off) and it needs to be written.
The next level of complexity is for example a new BRDF or material model – it will have to be integrated in a material editor, textures processed through platform pipeline and baking, compressed to the right format, shader itself generated and combined with other features… All while not breaking the existing functionality.
Finally, if you propose something to replace mesh representation you need to consider that suddenly the whole ecosystem that artists have used – from content authoring like Z Brush, 3D Studio Max and Maya, animation tools and exporters like Motion Builder or dedicated mocap software, to finally all engine plugins, importers/exporters. This is like redoing work of the decades of the whole industry. Doable? Sure. Reasonable? It depends on your budget and the benefits it might bring.
I have a theory about the popularity of engines like Unity and Unreal Engine – it didn’t come from any novel features (though there are many!), but from the mature and stable, expressive, and well known tooling (see below).
Education and experience
Some video game artists have been around for a few decades and built lots of knowledge, know-how and experience. Proposing something that doesn’t build on it can be a “waste” of this existing experience. To break old habits, benefits have to be huge, or become standard across the whole industry (Physically Based Rendering took a few years to popularize).
If you want to change some paradigms, are you able to spend time educating people using those in their daily work, and would they believe it is truly worth it?
Support of the others
It took me a while and some hard lessons to realize that the “emotional” side of collaboration is more important than the technical one.
If your colleagues like artists or other programmers are excited about something – everything will be much easier. If the artists are not willing to change their workflow, or don’t believe that something will help them, the whole feature or project can fail.
I have learned it myself and only in hindsight and hard way: early in my career I was mostly on teams with people similarly excited and similarly junior as me; so later on and on some other team the first time I proposed something that my colleagues didn’t care for, I didn’t understand the “resistance”, proceeded anyway, and the feature has failed (simply was not used).
Good “internal marketing”, hype, and building meaningful relationships full of trust in each other’s competence and intentions are super important and this is why it’s hard to ship something if you are an “outsider”, consultant, or a remote collaborator.
Testing
I’ve written a post about automatic testing of graphics features, and it goes without saying that productionizing anything takes many months of testing – by the researcher/programmer themselves, by artists, QA.
Anything that is not tested in practice can be assumed to be broken, or not working at all.
Debuggers and profilers
Every feature that requires some input data needs to provide means of validation and debugging behaviors and this input. Visualizations of intermediate results, profilers showing how much time is spent on different components, integration with other debugging tools.
Most graphics programmers I know truly enjoy writing those (as they both look cool, and pay off the time investment very quickly), but it has to be planned, costs time and needs to be maintained.
Developing a new technique, try to think “if things go wrong for some reason, how myself or someone less technical will be able to tell why and fix the problem? What kind of tools are needed for that?”
Edge cases
Ah, the edge cases. Things that are supposed to be “rare” or even negligible, but are guaranteed to happen during actual, large scale production. Non-watertight or broken topology meshes? Guaranteed. Zero-area triangles? Guaranteed. Flipped normals? Guaranteed. Materials with roughness of exactly zero? Sure. Black or fully white albedo? Yes. This one level where the walls have to be so thin that the GI leaks? Yep.
Production is full of those – sometimes to the extent that what is considered a pathologically bad input in a research paper, represents most of in-game assets.
Many junior graphics programmers who implement some papers in the first months of their careers, find out that described techniques are useless on the “real” data – hitting an edge case on literally the first tried asset. This doesn’t encourage future experimentations (and to be fair – could be avoided if authors were more honest in the “limitations” sections of publications and actually explored it more).
Practitioner mindset is to think immediately “How can this break? How can I trigger this division by zero? What happens if x/y/z?” and generally preparing to spend most of the time handling and robustifying those edge cases.
Production budget
Finally, something obvious – the production budget. Everything added/changed/removed from production has a monetary cost – of time, software licenses, QA, modifying existing content, shifting the schedule. Factoring it in is difficult, especially from an engineer position (limited insight into full costs and their breakdown), but tends to come naturally with some experience.
Anecdote from Witcher 2 – the sprite bokeh was something I implemented during a weekend ~2 weeks before gold master. I was super excited about it, and so were the environment and cinematic artists. We committed to shipping it and between us spent the next two weeks crunching to re-work the DoF settings in all existing cinematics (obviously many didn’t need to be tweaked, only some). Glad that we were super inexperienced and didn’t know not to do stuff like this – as the feature was super cool, and I cannot imagine it happening in any of my later and more mature companies. 🙂
Summary
To conclude, going from research to product in the case of graphics algorithms is quite a journey!
A basic implementation for a tech demo is easy, but the next steps are not:
- One needs to make sure the new algorithm can coexist with and/or support all the other existing product features,
- It has to fit well into an existing rendering pipeline, or the pipeline needs to be modified,
- All the aspects of the production process from tooling, through education to budgeting need to include it.
Severity of the constraints varies – from ones easy to satisfy, easy to workaround or hack, through more challenging ones (sometimes having to heavily compromise and drop them), but it’s worth thinking about the way ahead in the process and proper planning.
As I mentioned multiple times – I don’t want to discourage anyone from breaking or ignoring all those guidelines and “common knowledge”.
The bold and often “irrational” approaches are the ones that sometimes turn revolutionary, or at least are memorable. Similarly, pure researchers shouldn’t let some potential problems hinder their innovation.
But at the same time, if people representing both the “practical” and “theoretical” ends of the research and technology progress understand each other, it can lead to much healthier and easier “technology transfer” and more useful/practical innovation, driven by needs, and not the hype. 🙂
PS. if you’re curious about some almost 10 year old “war stories” about rendering of the foliage in The Witcher 2 – I tried to capture those below:
Supplement – case study – foliage
I started with a joke about how foliage rendering breaks everything else, but let’s have a more serious analysis into how much work and consideration went into rendering of Witcher 2’s foliage.
Around the time I joined CD Projekt Red in The Witcher 2 pre production, there was no “foliage system” or special solution for rendering vegetation. Artists were placing foliage as normal meshes – grass blade one after another on a level. Every mesh was a component and object inside an entity object, and generally was very heavy and using “general” data structures, same no matter if for rocks, vegetation, or the player character. Throughout the production a lot had to change!

Speedtree importer and wind
One of key artists working on vegetation was using Speedtree middleware a lot – but just as an editor, we were not using their renderer.
Speedtree supports amazingly looking wind, and artists wanted similar behavior in game. One of my first graphics related tasks was adding importing of some wind data from Speedtree into the game, and translating some of the behavior into our vertex shaders.
This was mostly tooling work, and took a few weeks – I needed to modify the tools code, add storage for this wind data, different vertex shader type, material baking code, support wind on non-speedtree assets. All for just supporting something that existed and wasn’t any kind of innovative/research thing.
But it looked great and I confirmed to myself that I was right dreaming of becoming a graphics programmer – it was so rewarding!
Translucency and normals
The next category of tasks with foliage that I remember working on was not implementing anything new, but debugging. We had a general “fake translucency” solution (emulating scattering through inverse boosted Lambertian term). But it relies on the normals pointing away, while our engine supported two sided normals (a mesh face normal flipped depending on which side it is rendered from) and some assets were using it. Similarly, artists were “hacking” normals to point upwards like the terrain to avoid some harsh lighting and smooth everything out, and such meshes didn’t show translucency, or it looked like some wrong, weird specular.
Fixing importers, mesh editor, and generally debugging problems with artists, and educating them (and myself!) took quite a bit of time.
To alpha test, or to draw small triangles?
As we were entering more performance critical milestones, foliage was more and more of a performance problem. Alpha testing is costly and causes overdraw, while drawing small triangles causes so-called quad overdraw. Optimizing the overdraw of foliage was a never ending story – I remember when we started profiling some levels, there was a single asset that took 8ms to render on powerful PCs. We did many iterations and experiments to make it run fast. In the end, the solution was hybrid – many single grass blades, but leaves were organized as alpha tested “leaf cards”.
Level layer meshes
One of the first important optimizations – just for the part of the CPU cost, and reducing loading times – was to “rip” all meshes that were simple enough (no animations other than wind, no control by gameplay) into a separate, much smaller data representation.
This task was something I worked on with lots of mentorship from a senior programmer, and was going back to my engine programming roots (data management, memory, pipeline).
While it didn’t address all the foliage needs, it was a first step that allowed to process tens of thousands of such objects (instead of hundreds), and artists realized they needed better tooling to populate a large world.
Automatic impostor system
A feature that my much more senior colleague worked on – adding the option of automatic impostor generation. After an user-defined distance, mesh would turn into an auto-rotating billboard – with different baked views from different sides.
While I didn’t implement it, later was improving and debugging it quite a lot (the programmer who implemented it was the most senior person on the team overwhelmed with tasks and generally often worked by doing initial implementation and then handling it off to more junior people – and it was a great learning and mentoring opportunity) on things like inpainting alpha tested regions for correct mip-mapping, or how to optimize backing w.r.t. the GBuffer structure (to avoid extra GBuffer packing/unpacking).
Foliage editor
The next foliage specific work was again around tooling!
Our senior programmer spent a few heavy weeks on making a dedicated foliage editor, with brushes, layers, editors. Lots of mundane work, figuring out UX issues, finding best data representations… Things that need to happen, but almost no paper will describe.
The result was quite amazing though, and during the demo, my colleague showed the artists how he was able to create a forest in 5minutes and right away, our game got populated by them with great looking foliage and vegetation (in my biased opinion, the best looking in games around that time).
Foliage culling and instancing
With lots of manual optimization work, we were nearing the shipping date of Witcher 2 on PC and starting to work on the X360 version. A newly hired programmer, now my good friend, was looking into performance, especially on the 360 of the occlusion culling (an old school “hipster” algorithm that you probably never heard of, a beam tree). Turns out that building a recursive BSP from hundreds of occluders every frame and processing thousands of meshes against it is not a great idea, especially on an in-order PowerPC CPU of X360.
My colleague spent quite a lot of time on making the foliage system a real “system” (and not just a container for meshes) with hierarchical representation, better culling, and hardware instancing (which he had experience with on X360, unlike anyone else in the team). It was many weeks of work as well, and absolutely critical work for shipping on the Xbox.
Beyond Witcher 2 – terrain, procedural vegetation
This doesn’t end the story of vegetation in Witcher games.
For Witcher 3 (note: I barely worked on it; I was moved to the Cyberpunk 2077 team) my colleagues went into integration of the terrain and foliage systems with streaming (necessary for an open world game!), while our awesome technical artist coded procedural vegetation generation inspired by physical processes (effects of altitude, the amount of sun, water proximity), and “game of life” that were used for “seeding” the world with plausibly looking plants and forests.
I am sure there were many other things that happened. But now imagine having to redo all this work because of some new technique – again, doable, but is it worth it? 🙂

Thanks for the article. Really insightful for an aspiring graphics dev. I’m surprised how much of the rendering techniques are implemented in-house rather than using what a game engine like UE4 or Unity offers (assuming that’s the case on the projects you’ve worked on..)!! Are there any aspects of the pipeline that devs recycle and reuse on the next projects or is everything pretty much scrapped?
A few more questions:
What do you think is the biggest change in graphics in video games that maybe covered/passed the test on all of these aspects you’ve mentioned? How was it received among the teams when introduced?
Do you know of any upcoming research or existing research papers that are soon going to be implemented in video games?
Usually, in a team like AC4, are graphics devs expected to consider all of these things at all times in their work? More precisely, how specialized is each engineer?
On the emotional side: Do you think there is a way to present the idea in a way that will excite your colleagues? What kind of factors determine their excitation for a new technology? From the way you presented, I feel like the hype is intrinsic to their personal taste. Also, would you recommend a junior to “proceed anyways” on ideas like you had? I personally think of time and money that could potentially be wasted on preparing a plan and prototypes haha.
Lastly, how does the whole integrating new research thing work? Are devs usually expected to read up on new tech every day, and then there’s a period in the project dedicated to researching new tech and getting together to test them?
Again, thank you! Loved waking up to this 🙂
Hi Trang,
Thanks for your insightful questions and comments.
1. Re UE / Unity and custom engines:
I’d say that still most of the AAA games use in-house tech. All big developers / publishers like EA, Ubisoft, Activision have own engines, sometimes multiple (like Dunia, Scimitar, Snowdrop at Ubisoft). Most Sony first-party games are also on custom engines; or companies like CDPR or Rockstar also use own tech. I am skeptical if one can create an open world game without a custom engine.
I have always worked on such in-house engines and was an engineer actually writing them. 🙂
Between games a lot of technology is preserved, but usually branched out some time before release – as the release period means lots of game specific hacks and “shipping” – things that only add tech debt.
2. Re biggest large changes in game engines – I’ll stick to the rendering side and IMO two biggest revolutions were introduction of physically based rendering/shading and all the implications – gamma correctness, PBR materials, HDR lighting etc. This was a huge, multi-year endevour and is still not fully “over” (never will be; PBR is more of a philosophy). Second huge change was introduction of TAA and temporal techniques. This was a game changer and in hindsight prolonged life of deferred shading.
3. For upcoming research in video games, there is lots of traction around raytracing – and I think it’s cool and there to stay as it simplifies some problems. But it’s not a replacement for rasterization, just yet another tool that actually *increases* the pipeline complexity.
Second area of potential change for content creation that I think has 50% chances of succeeding is usage of ML for content creation – assets, textures. Depends if researchers and engineers can make it artist-friendly and provide meaningful controls, plus the artist resistance against such tech.
4. Nobody expects a single engineer to understand it all in 100% details. The more senior you are, the more “mature” should be your suggestions, and consider many things, but it’s ultimately about teamwork with specialists. At Sony I was the technical architect and my role was managing lots of this complexity, but I didn’t know every single detail and a lot was about asking proper experts about their opinions. So generally junior engineers can drift away, but that’s ok, their lead (or senior programmers, or a tech architect) should be able to pinpoint such challenges.
5. I don’t have an easy answer for the emotional aspect.
For sure don’t believe in “objective data” and “metrics driven” things – this is a lie and a point of view of technocrats; people don’t work this way. The best solution is to have a close, meaningful relationship with peers, discuss ideas often and get the feeling if they are excited or not. Partner up with an artist who will make a cool showcase of the tech. Solve actual real and up-to-date problem (different at different production stages). Lots of loose ideas, no clear guidelines…
And whether I’d recommend “proceeding anyway”… it depends. If it’s something you do in your spare time, go ahead, have low expectations, but if you believe in it and it’s fun, why not. If on the other hand everyone is just crunching to finish the game and you only want to push some new ideas in regular working hours, expect people upset about it…
6. For the final questions, most game graphics engineers don’t read papers and don’t care about academic research – as they have been burnt too many times with impractical techniques. Most of the time it’s about solving some real production problems and thinking “how can I approach it?” and then looking for potential answers/solutions.
And this can happen at any production stage! Obviously if something changes the pipeline, it should be finalized in preproduction; but some clever new ways of rendering that optimize performance or improve the image quality can happen even in the last few weeks / for the patches.
Cheers!
Amazing article!
I wonder if it is possible, for the sake of less experienced readers, to add a list of links to some resources that would expand on (some of) the technologies that you briefly mention here as something that goes without saying, but that might be not as familiar for some of us?
I’ll try to add some later, the main challenge is that quite a lot of this knowledge is not very formalized. Often it’s spread out through casual presentations incrementally evolving the field – and they almost always assume someone is kind of an expert already… Anytime beginners ask for advice how to get into the field, it’s similarly difficult. But one resource that is great and I’ll already recommend is the “Real Time Rendering” book, it’s fantastic and covers probably most of the described concepts.