While this post is not yet dithering related, it is in a way a part of my series about dithering. You can check index of all parts here or check the previous part.
I will talk here about use of not very popular / well knows format R11 G11 B10 Float (R11G11B10F) format – its precision, caveats and how to improve it.
I want to note here that this post will not touch on many float subtleties, namely NaNs, denorms and infinities. Lots of GPU shader compilers use fast math anyway (unless asked to do strict IEEE compliance) and ignore them – and programmers have to be double careful when their used values.
You can find Mathematica notebook for this post here and corresponding pdf here.
Update: I updated section about losing dynamic range in denorm range after correction from Tom Forsyth and Peter Pike-Sloan that GPUs are standardized to support denorm on write to small floats.
Problem description
Most common representation of colors in rendering is not integer / natural / rational number representation, but floating point representation. Floating point numbers and their large range are useful for few different reasons, but the most important are:
- Encoding HDR values and lighting,
- Need for fractional values when operating on multiple colors, mixing them, filtering with filters with fractional or negative weights,
- Need for larger precision in darker areas without any gamma encoding,
- Need for bound relative quantization error (constant upper bound relative to signal magnitude),
- Fact that floating point numbers are “natural” representation for GPUs (for a long time GPUs didn’t have any integer number support or it was “emulated” using float operations… And still some integer operations are slower than floating point operations).
That said, rendering techniques very rarely store 32bit floating point values even for HDR color – because of both memory storage cost as well as performance. Memory bandwidth and caches are usually most sacred resource and simplistic rule of thumb is “ALU is cheap, memory access is expensive”. Even simplest memory access operations have latencies of hundreds of cycles (at least on AMD GCN). Furthermore, cost increases when texturing unit is used – as filtering operations get more and more expensive and operate with slower rates.
Therefore, rendering programmers usually use smaller float formats as intermediate in-memory storage – 2 most common being RGBA16F (4 16bit half float channels) and R11G11B10F (channels R and G having 11 bit small float and channel B using 10 bit small floats).
Let’s have a look at the difference between those formats and full 32bit IEEE float. If you feel comfortable with float representation, feel free to skip the next section.
Floats – recap
I am assuming here that reader knows how floating values are represented, but as for a reminder – typical floating point value is represented by some bits for:
- sign – just sign of the number, max single bit value and optional (more later),
- exponent – some bits that are represented in biased, integer format and describe biased exponent of number of 2 before multiplying with rest of the number,
- mantissa – some bits representing the fractional part of the number before multiplying by exponent. It is assumed that there is a leading 1, decimal point, so for example mantissa of 01011000 corresponds to number 1.01011000 represented binary (in base of 2).
Therefore final typical number is sign(+/- 1) * 2decoded exponent * 1.mantissa.
There are lots of “special” cases of floats that use special smallest and largest values of exponent (denorms, infinity, NaN, zero), but for the purpose of this post, we will have a look later at only one special case – encoding of zero – it is achieved by putting all exponent and mantissa bits to zero. (note: because sign can be still set, there are two zeros, +0 and -0).
Floating points are a very clever representation with lots of nice properties (for example positive floats interpreted as integers can be sorted or atomically min/maxed! Or that integer zero corresponds to just positive float zero), however come with many problems with precision that are not always the most intuitive. I will be mentioning here only some of them – the ones that are relevant to discussed problem.
Regular and small floats
So far I was trying to stay very generic and not specify any bit numbers, but to use floats in hardware (or software emulation), we need to define them.
Here is a table showing various bit depths of regular 32 bit floats as well as half floats and 11 and 10 bit floats as used by graphics hardware / standards:
| Bit depth | Sign bit present? | Exponent bits | Mantissa bits |
| 32 | Yes | 8 | 23 |
| 16 | Yes | 5 | 10 |
| 11 | No | 5 | 6 |
| 10 | No | 5 | 5 |
We can immediately see few interesting observations:
- 11 and 10 floats do not have sign bit! This decision was probably driven by the fact that they have already quite poor precision for most of uses, so they were designed in graphic APIs only to store color; using a sign bit here would be an extra waste.
- 16 bit “half” floats and 11 and 10bit floats all have same exponent! This is pretty interesting choice, but it guarantees that they can represent +/- similar range of values. Exponent of 5 guarantees that values can go to 65500 and 65000 (depending on their mantissas), which is pretty large even for HDR lighting (unless using non-biased, absolute exposure values or doing increasing precision trick I will cover later). Exponent can be negative, so we can go to similarly (“one over”) low values.
- Mantissa suffers the most. The difference is quite crazy – 23 vs. 5 bits in the worst case! We are dropping 18 bits of precision. This is very unfortunate information, as it means that relatively, between numbers that are in similar range (similar exponent), we are losing lots of precision.
Also, because of different bit depths of 11 11 10 float format, problem arises from different mantissa bit depths of blue channel and other channels – it will produce various discolorations and hue shifts – similar to ones that appear often in BC1 block compression (with 565 endpoint bit depths), but not being green/purple, but yellow/blue instead. I will show an example of it later in the post. Obviously, this decision makes sense – 11 11 10 format fits nicely in a single dword and perceptually, human vision is least sensitive to blue channel.
So as we see, we are dropping lots of information by converting 32 bit floats to 16 or 11/10 bits. Furthermore, information loss is not proportional between exponent and mantissa – in every small float case, we lose much more information in the mantissa. This can lead to some quantization and banding errors.
Before analyzing quantization, one thing is worth mentioning – IEEE standard defines few different rounding modes (e.g. to nearest, to zero, to +inf and to -inf). I don’t think they are in any way configurable on GPUs (at least in standard, cross vendor APIs) and I will write rest of the post ignoring this complexity and assuming that simplest rounding is used.
Small float mantissa precision – concrete example
I hope that previous section and looking at some numbers for bit depths shows clearly problem of losing lots of numerical precision of smaller format floating point numbers because of very small mantissa.
First, some numerical example. Let’s take 3 simple, 8 bit integer values and represent them as a float in range 0-1 – common operation for colors.
N[252/255, 8]
0.98823529N[253/255, 8]
0.99215686N[254/255, 8]
0.99607843
Let’s try to represent them as floats. Using knowledge about float values and knowing that mantissa always starts with one, we need to multiply them by 2 and exponent will be 2-1.
After multiplication we get:
BaseForm[N[2*252/255, 8], 2]
1.1111100111111001111110100BaseForm[N[2*253/255, 8], 2]
1.1111101111111011111111000BaseForm[N[2*254/255, 8], 2]
1.1111110111111101111111100
I highlighted the first 5 bits, why? Recall that 10-bit half float has only 5 bits of mantissa! Therefore 10bit half floats (blue channel of R11 G11 B10F) cannot represent accurately even 3 almost-last 8 bit color values! At the same time, you can see that the next bit actually differs – therefore those 3 numbers will produce 2 different values in 11F and produce wrong coloration of white values.
Small float mantissa precision – visualized
Ok, so we know that small floats cannot represent accurately even simple 8bit luminance! But how bad they really are? I created some Mathematica visualizations (see top of the page for link) – first for the worst case, B10F, so dropping 18 bits of mantissa.

Things look ok (or even much better – not surprising given how floats are encoded!) close to zero, but error starts increasing and is almost 4x larger close to one compared to linear 8 bit values quantization error!
This comparison however is quite unfair – we don’t use 8bit linear color because of perceptual sensitivities to darks vs brights (“gamma”) and use sRGB instead, so don’t care as much about those bright areas and decide to encode more information into darker parts. This is how comparison of those 3 methods of encoding look like:

Ok, things are a bit more even. Looks like 10bit float precision is a bit better for values up to linear 0.125, but later get worse. Maximum error is almost 2x larger around 1 for 10 bit floats, not great… This will create visible bands on smooth gradients.
Just for fun, extra visualization, relative error (divided by original value):

As expected, float value quantization relative error is bounded and has a maximum in ranges corresponding to next exponents (if we don’t count here going lower than minimum normalized float representation), while 8 bit linear or sRGB relative errors increase as we approach zero. Floating point relative error is also represented in “bands” corresponding to next exponents and getting 2x larger between 2 adjacent bands.
We will have a look at how to improve things a bit, but first – a bit more about a second problem.
Small float uneven mantissa length problem
Because R11G11B10 floats have uneven mantissa bit length distribution, they will quantize differently. How bad is it? As always with floats, absolute error depends on the range:

The larger the number – the higher the error. In last part of the plot it looks pretty bad:

What this different quantization mean in practice? It means that there will be discoloration / wrong saturation of the signal. Let’s have a look at a simple gradient from 0.5 to 0.6.

This is very bad (if you have a good monitor / viewing conditions). And now imagine that art director that you work with likes contrasty, filmic look with saturation boosted:

This looks quite unusable… We will have a look at improving it. In this post by changing the signal dynamic range, in the next post by dithering.
Rescaling will not work
Quite common misconception is that it is enough to multiply a float by large number, encode it and divide after decode. It is not going to work, for example, let’s see quantization error when premultiplying by 16:
Zero difference at all! Why? Let’s think what it means to divide by 16 in float representation. Well, mantissa is not going to change! Only thing is that we will subtract 4 from the exponent. So relative error due to mantissa quantization will be exactly the same. One can try to multiply by a number between 1/2 and 2 and we will see a difference in ranges shifting, but it is going to only shift error to either more white or more dark parts:
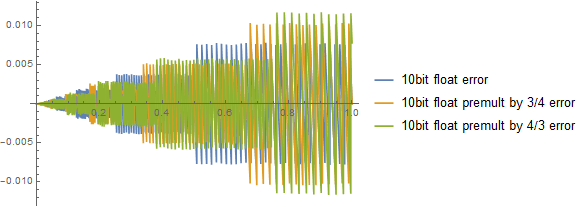
Error bands only slide left or right.
Improving error by applying some gamma
Let’s have a look here at a different method – that will take advantage of the fact that probably (if image is pre-exposed!) we don’t care about extremely small values, where most precision is positioned (to achieve bound relative precision).
I mentioned in my previous post about dynamic range commonly used workaround for shifting precision precision problems – stretching the dynamic range by taking some power of the signal (smaller or larger). For storing higher precision dark areas of images in integers, we wanted to take lower power for encoding – for example famous gamma 1/2.2. However, in this case we would like to do… the opposite! So taking larger power – to understand why, just look at the original comparison where we introduced sRGB variant: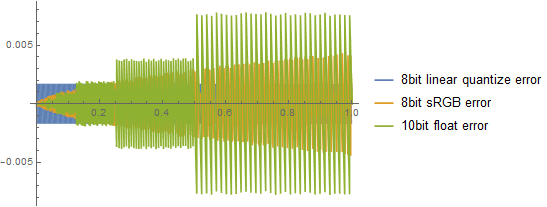
We rescaled blue plot from constantly oscillating in fixed bounds to one that grows. Here with 10bit floats the problem is opposite – we have a function that asymptotically grows too quickly – we want to undo it.
Think a bit about it, it’s quite interesting problem. It has a lot to do with the way floats precision is distributed – it is non-linear, logarithmic distribution that handles large dynamic ranges very well; furthermore, exponential-like signal curve will be represented almost linearly! Therefore to take the most from our floating point representation with low bit depths, we would like to increase dynamic range as much as we can prior to encoding. We can do it by for example squaring the signal or taking larger powers. For the initial 3 floats that I used this requires actually quite large exponent, 3 for given values:
BaseForm[N[2*(252/255)*(252/255)*(252/255), 8], 2]
1.1110111000100100001001000BaseForm[N[2*(253/255)*(253/255)*(253/255), 8], 2]
1.1111010000001100000101000BaseForm[N[2*(254/255)*(254/255)*(254/255), 8], 2]
1.1111101000000000000001000
Note how they are different (though first two will round the same way).
Let’s have a look at absolute error with applying gamma 3 (note: this graph assumes correct denorm handling, more below):

Our error looks asymptotically smaller than 8bit sRGB error – this could be already quite useful storage base. Our previously banded gradient also looks better, as well as its higher contrast version (though not perfect – recall that contrast kind of redoes the gamma):
Before:

After:

Before with contrast:

After with contrast:

There is no free lunch though!
First of all, there is ALU cost. As we do this operation per 3 channels, it can get quite significant! Taking x*x*x is 2 full rate operations, but for example pow(x,1/3) is log2 + exp2 + multiply, so 2 quarter rate + 1 full rate = 9 FR instructions per color channel! Cheapest variant is just squaring and sqrt(x) is a single quarter rate instruction = equivalent of 4 FR instructions.
Secondly, this data is now obviously not filterable / blendable… Blending in this space wold ceate over-brightening. This can be an issue (if you need hw blending or to resample it with bilinear taps) or not (if you can do it all manually / in a compute shader).
Thirdly, this extra precision is achieved by sacrificing the dynamic range. It is +/- equivalent to dividing abs value of exponent by the used gamma. So for example, with gamma 3 our maximum representable value will be around pow(65000,1/3) ~= only 40! Is it HDR enough for your use? If pre-exposing the scene probably yes, but hottest points will be clipped… The squared variant looks much better, as around 250+.
Potential problem with small numbers
Note: this section got slightly rewritten after correction from Tom Forsyth and Peter Pike-Sloan. My assumptions were pessimistic (denorm flush to zero), but apparently, GPUs in for example DirectX are obliged to handle them correctly. Thanks for noticing that!
Another problem could be in a different part – smallest representable numbers. The same abs of exponent division is applied to smallest representable numbers! Therefore smallest normalized representable number after applying gamma 3 will be 0.03125, which is around 8/255 and if we don’t have denorms or denorms are flushed to zero, this would result in a clip! Without handling denorms, the zoomed-in actual graph of error would look:
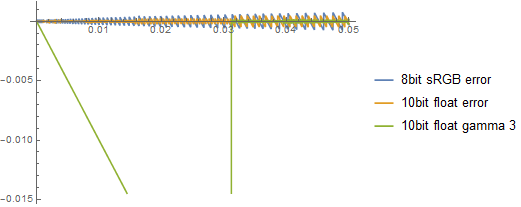
As the graph would look:
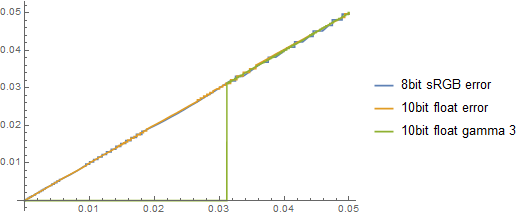
You could try to fix it by preexposing for example by 4:
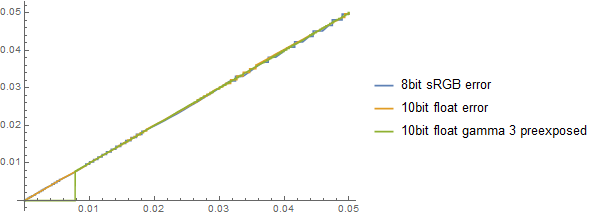
But not only it’s not perfect, but also you’d start losing it again from the top range. (hottest representable values) Instead of already limiting 40, you’d get only 10! This is probably not enough even for displaying the signal on a HDR TV…
Therefore, if denorms were not handled correctly, I’d rather recommend to stick to gamma 2 with preexposure of 4 and accept the slightly higher quantization errors:
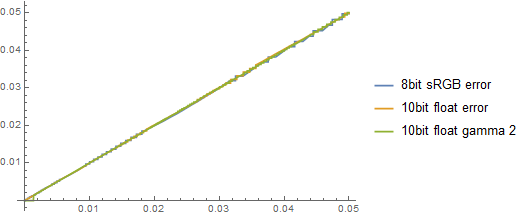
Fortunately, as I got corrected – this is not the case and we can assume that denorms will be handled – so can use those higher exponents if needed – only thinking about how much dynamic range we are sacrificing in the upper/higher parts.
Before finishing this section, interesting side note: have you ever considered how low is normalized float precision when operating on 16 bit floats? Half floats have same exponent bit depth, so if you apply contrast operations to them, you might be entering denorm range very quickly! Which theoretically could result in clipping.
Untested idea – using YCoCg color space?
Some interesting (?) idea could be trying to use some different color space like YCoCg or similar instead of RGB. In (signed) YCoCg smaller chroma = smaller magnitudes of Co Cg components = more precision. This would help decorrelate color channels and avoid ugly chroma shifts when the color is less saturated (and when those shifts are more visible).
Unfortunately, R11G11B10 has no sign bit available – we would need to store 2 extra sign bits “somewhere” (different surface? lowest bit of mantissa / highest bit of exponent?).
Summary – to use R11G11B10F or not to use?
R11G11B10 and small 11 and 10 bit floats have many limitations, but are also extremely compelling storage format. They halve memory storage and bandwidth requirements compared to RGBA16F, are capable of storing high dynamic range signal and after some numerical tricks also provide precision acceptable in most color encoding scenarios. I use them a lot to non critical signals (ambient buffer, many post effects buffers), but I think that they are practical also for regular color buffers if you don’t need alpha blending or filtering and can tinker with the input data a bit.
Update: I got information from Volga Aksoy and Tom Forsyth that Oculus SDK now supports and recommends outputting into this format, so it is definitely practical. Because of darker / perfect viewing conditions with a HMD, human perception is much more sensitive in darks and R11G11B10F performs better than 8bit sRGB in this lower range.
In the next post I will show how to dither floats and get even better results with almost no perceived banding (trading it for noise).
Bonus – comparison with 10bit sRGB
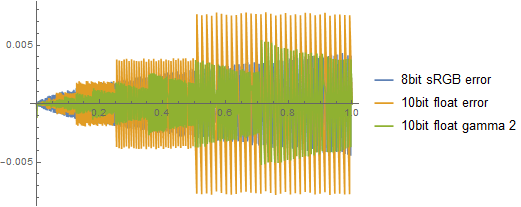
As a small bonus, simple comparison with 10bit sRGB encoding (no hardware support, but some video out libraries support it to allow for more precise color profile / curves conversions). Two plots show error in full 0-1 range and in 0-0.1 darks range.


We can see that 10bit sRGB is much more superior throughout most of the range, but in very low/dark values 10bit floats are either equivalent or even a bit more superior.
References
https://www.opengl.org/wiki/Small_Float_Formats
http://steve.hollasch.net/cgindex/coding/ieeefloat.html Steve Hollasch, “IEEE Standard 754 Floating Point Numbers”
http://community.wolfram.com/groups/-/m/t/274061 Mathematica help – Convert floating point representation to any scientific notation & back
https://msdn.microsoft.com/en-us/library/windows/desktop/cc308050(v=vs.85).aspx#alpha_11_bit Direct3D 10 Floating point rules

Hi,
First of all, thank you for the very good explanations :-).
After reading your article I wanted to try the dithering on floating point values you mentioned.
Here is my attempt to apply dithering on a 32-bit float triplet before quantizing to R11G11B10F: https://www.shadertoy.com/view/4slBDl
Is that what you had in mind?
Hey, I was trying with similar approach but with integers and direct operations on mantissa – bitshifting etc, but was never able to get good results because of how floats are piecewise linear/asymmetric. So this approach works well in middle of a linear curve corresponding to some exponent, but breaks close to either of its ends.
To try to explain it – if I find some multiplier range at the end of the linear curve piece – it will be too low for the following, more steep linear curve piece. You would under-dither. And vice versa – if you find multiplier close to beginning of the range, then when taking triangular distribution -0.5, 1.5, you can overshoot whole range completely.
It might be not a huge deal in practice though after sliightly increasing the range even more, as not too strong over-dithering doesn’t look bad. 🙂
Instead I used a different approach recommended to me by my ex co-worker – not using hw rounding at all, but adding random noise within mantissa bits and taking a floor. Sadly this makes it possible to dither only in 0-1*lost bits range, doesn’t support for example triangular distribution…
I’m not sure that I follow..
My assumption was that the precision of a float is constant between two powers of two and can be computed as follow for a given float f: epsilon(f) = exp2(E – nbitsMantissa(f)) with E such as exp2(E) <= f < exp2(E+1).
So between two ranges, the epsilon value doubles. This introduces indeed overshooting on the left side at the very beginning of a range and undershooting on the right side of very of a range. Under/overshooting only occurs at the borders of a range and is one epsilon off.
Do I make sense or am I completely wrong ^^' ?
Yes, it makes total sense and it was exactly my point. 🙂 Is it a big issue? I don’t know, would need to run some simulation. Alternative I talked about is instead of hw rounding adding some random mantissa bits and doing an integer truncation with “and” mask.
Hey Bart,
I wonder if you have any thoughts on how R11G11B10F compares against LogLUV, both are/seem quite compelling formats for storage of a HDR color without alpha.
Hi! I haven’t thought too much about comparing to other manually packed formats like this. There are many applications where they excel and fit the range way better that small floats, but I wanted to focus here on analyzing something that is built in the hardware and has full support for interpolation, blending, and doesn’t require any extra math by default.
Many of manually packed formats get much better precision or number distribution for given applications, but at a cost of extra ALU for packing and/or sacrificing interpolation or blending…
Doing numerical error analysis would nevertheless be very interesting! 🙂
Hi Bart,
“Blending in this space would create over-brightening” , you said. But blending in gamma space (1/2.2 is supposed) usually results a darkened look.
Power[Power[0, 1/2.2]*0.5 + Power[1, 1/2.2]*0.5, 2.2]
= 0.217638
Do I get it wrong?
Yes, however this space is the opposite – it is squaring, and not sqrt!
OK, I misunderstood what you meant in this article.
I have another question. Where does the 1/32768 come from in your Mathematica notebook? I thought it might be the smallest 10-bit floating, but it should be 2^-14=1/16384 without denorms.
I don’t remember where it comes from, maybe 1/max value -> so this would be an error, as bias is asymmetric. Worth double checking.