
Introduction
The technique was first mentioned by Crytek among some of their improvements (like screenspace raytraced shadows) in their DirectX 11 game update for Crysis 2 [1] and then was mentioned in couple of their presentations, articles and talks. In my free time I implemented some prototype of this technique in CD Projekt’s Red Engine (without any filtering, reprojection and doing a total bruteforce) and results were quite “interesting”, but definitely not useable. Also at that time I was working hard on The Witcher 2 Xbox 360 version, so there was no way I could try to improve it or ship in the game I worked on, so I just forgot about it for a while.
On Sony Devcon 2013 Michal Valient mentioned in his presentation about Killzone: Shadow Fall [2] using screenspace reflections together with localized and global cubemaps as a way to achieve a general-purpose and robust solution for indirect specular and reflectivity and the results (at least on screenshots) were quite amazing.
Since then, more and more games have used it and I was lucky to be working on one – Assassin’s Creed 4: Black Flag. I won’t dig deeply into details here about our exact implementation – to learn them come and see my talk on GDC 2014 or wait for the slides! [7]
Meanwhile I will share some of my experiences with the use of this technique and benefits, limitations and conclusions of my numerous talks with friends at my company, as given increasing popularity of the technique, I find it really weird that nobody seems to share his ideas about it…
The Good
Advantages of screenspace raymarched reflections are quite obvious and they are the reason why so many game developers got interested in it:
- Technique works with any potential reflector plane (orientation, distance) and every point of the scene being in fact potentially reflective. It works properly with curved surfaces, waves on the water, normal maps and different levels of reflecting surfaces.
- It is trivial to implement* and integrate into a pipeline. It can be completely isolated piece of code, just couple of post-effect like passes that can be turned on and off at any time making the effect fully scalable for performance considerations.
- Screenspace reflections provide a great SSAO-like occlusion, but for indirect specular that comes from for example environment cubemaps. It will definitely help you with too shiny objects on edges in shadowed areas.
- You don’t require almost any CPU cost and potentially long setup of additional render passes. I think this is quite common reason to use this techniques – not all games can manage to spend couple millis on doing a separate culling and rendering pass for reflected objects. Maybe it will change with draw indirect and similar techniques – but still just the geometry processing cost on the GPU can be too much for some games.
- Every object and material can be reflected at zero cost – you already evaluated the shading.
- Finally, with deferred lighting being an industry standard, re-lighting or doing a forward pass for classic planar / cube reflectors can be expensive.
- Cubemaps are baked usually for static sky, lighting and materials / shaders. You can forget about seeing cool sci-fi neons and animated panels or on the other hand your clouds or particle effects being reflected.
- Usually you apply Fresnel term to your reflections, so highly visible screenspace reflections have a perfect case to be working – most of rays should hit some on-screen information.
We have seen all those benefits in our game. On this two screenshots you can see how screenspace reflections easily enhanced the look of the scene, making objects more grounded and attached to the environment.

AC4 – Screenspace Reflections On

AC4 – Screenspace Reflections Off
One thing worth noting is that in this level – Abstergo Industries – walls had complex animations and emissive shaders on them and it was all perfectly visible in the reflections – no static cubemap could allow us to achieve that futuristic effect.
The Bad
Ok, so this is a perfect technique, right? Nope. The final look in our game is effect of quite long and hard work on tweaking the effect, optimizing it a lot and fighting with various artifacts. It was heavily scene dependent and sometimes it failed completely. Let’s have a look on what can causes those problem.
Limited information
Well, this one is obvious. With all of screenspace based techniques you will miss some information. On screenspace reflections they are caused by three types of missing information:
- Off-viewport information. Quite trivial and obvious – our rays exit viewport area without hitting anything relevant. With regular in-game FOVs it will often be the case for rays reflected from pixels located near the screen corners and edges.

Fail case #1 – offscreen information
- Back or side-facing information. Your huge wall will become 0 pixels is viewed not from the front side and you won’t see it reflected… This will be especially painful for those developing TPP games – your hero won’t be reflected properly in mirrors or windows.

Fail case #1 – offscreen information
- Lack of depth complexity. Depth buffer is essentially a heightfield and you need to assume some depth of objects in z-buffer. Depending on this value you will get some rays killed too soon (causing weird “shadowing” under some objects) or too late (missing obvious reflectors). Using planes for intersection tests and normals it can be corrected, but it still will fail in many cases of layered objects – not to mention the fact of lack of color information even if we know about ray collision.

Fail case #3 – lack of any information behind depth buffer


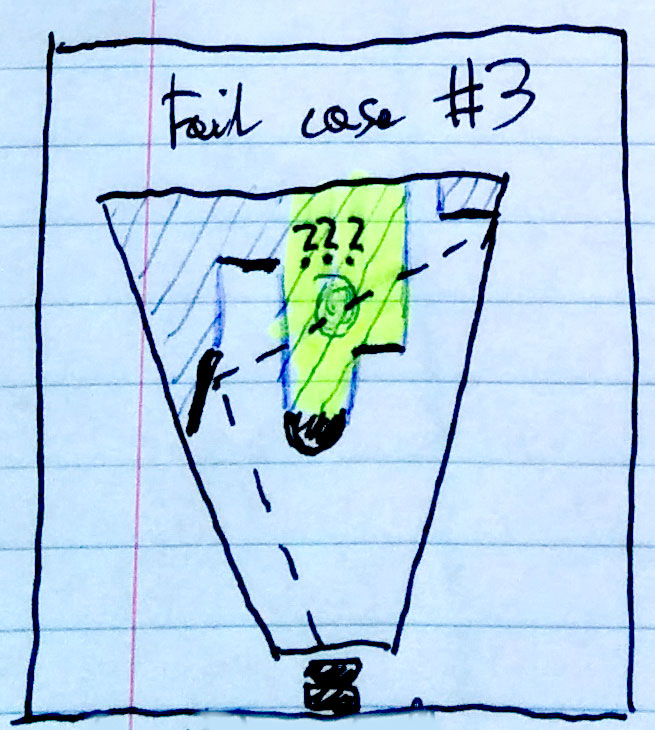
Ok, it’s not perfect, but it was to be expected – all of the screenspace based techniques reconstructing 3D information from depth buffer have to fail sometimes. But is it really that bad? Industry accepted SSAO (although I think that right now we should already be transiting to 3D techniques like the one developed for The Last of Us by Michal Iwanicki [3]) and its limitations, so what can be worse about SSRR? Most of objects are non-metals, they have high Fresnel effect and when the reflections are significant and visible, the required information should be somewhere around, right?
The Ugly
If some problems caused by lack of screenspace information were “stationary”, it wouldn’t be that bad. The main issues with it are really ugly.
Flickering.
Blinking holes.
Weird temporal artifacts from characters.
I’ve seen them in videos from Killzone, during the gameplay of Battlefield 4 and obviously I had tons of bug reports on AC4. Ok, where do they come from?
They all come from lack of screenspace information that is changing between frames or changes a lot between adjacent pixels. When objects or camera move, the information available on screen changes. So you will see various noisy artifacts from the variance in normal maps. Ghosting of reflections from moving characters. Suddenly appearing and disappearing whole reflections or parts of them. Aliasing of objects.
Flickering from variance in normal maps
All of it gets even worse if we take into account the fact that all developers seem to be using partial screen resolution (eg. half res) for this effect. Suddenly even more aliasing is present, more information is not coherent between the frames and we see more intensive flickering.

Flickering from geometric aliasing / undersampling
Obviously programmers are not helpless – we use various temporal reprojection and temporal supersampling techniques [4], (I will definitely write a separate post about them! As we managed to use them for AA and SSAO temporal supersampling) bilateral methods, conservative tests / pre-blurring source image, do the screenspace blur on final reflection surface to simulate glossy reflections, hierarchical upsampling, try to fill the holes using flood-fill algorithms and finally, blend the results with cubemaps.
It all helps a lot and makes the technique shippable – but still the problem is and will always be present… (just due to limited screenspace information).
The future?
Ok, so given those limitations and ugly artifacts/problems, is this technique worthless? Is it just a 2013/2014 trend that will disappear in couple years?
I have no idea. I think that it can be very useful and definitely I will vote for utilizing it in the next projects I will be working on. It never should be the only source of reflections (for example without any localized / parallax corrected cubemaps), but as an additional technique it is still very interesting. Just couple guidelines on how to get best of it:
- Always use it as an additional technique, augmenting localized and parallax corrected baked or dynamic / semi-dynamic cubemaps. [8] Screenspace reflections will provide an excellent occlusion for those cubemaps and definitely will help to ground dynamic objects in the scene.
- Be sure to use temporal supersampling / reprojection techniques to smoothen the results. Use blur with varying radius (according to surface roughness) to help on rough surfaces.
- Apply proper environment specular function (pre-convolved BRDF) [5] to this stored data – so they match your cubemaps and analytic / direct speculars in energy conservation and intensity and whole scene is coherent, easy to set up and physically correct.
- Think about limiting the ray range in world space. This will serve as an optimization, but also as some form of safety limits to prevent flickering from objects that are far away (and therefore could have tendency to disappear or alias).
Also some research that is going on right now on topic of SSAO / screen-space GI etc can be applicable here and I would love to hear more feedback in the future about:
- Caching somehow the scene radiance and geometric information between the frames – so you DO have your missing information.
- Reconstructing 3D scene for example using voxels from multiple frames’ depth and color buffers – while limiting it in size (eviction of too old and potentially wrong data).
- Using scene / depth information from additional surfaces – second depth buffer (depth peeling?), shadowmaps or RSMs. It could really help to verify some assumptions we take about for example object thickness that can go wrong (fail case #3).
- Using lower resolution 3D structures (voxels? lists of spheres? boxes? triangles?) to help guide / accelerate the rays [6] and then precisely detect the final collisions using screenspace information – less guessing will be required and maybe the performance could be even better.
As probably all of you noticed, I deliberately didn’t mention the console performance and exact implementation details on AC4 – for it you should really wait for my GDC 2014 talk. 🙂
Anyway, I’m really interested in other developer findings (especially the ones that already shipped their game with similar technique(s)) and can’t wait for bigger discussion about the problem of handling indirect specular BRDF part, often neglected in academic real-time GI research.
References
[1] http://www.geforce.com/whats-new/articles/crysis-2-directx-11-ultra-upgrade-page-2/
[2] http://www.guerrilla-games.com/presentations/Valient_Killzone_Shadow_Fall_Demo_Postmortem.html
[3] http://miciwan.com/SIGGRAPH2013/Lighting%20Technology%20of%20The%20Last%20Of%20Us.pdf
[4] http://directtovideo.wordpress.com/2012/03/15/get-my-slides-from-gdc2012/
[5] http://blog.selfshadow.com/publications/s2013-shading-course/
[6] http://directtovideo.wordpress.com/2013/05/08/real-time-ray-tracing-part-2/
[7] http://schedule.gdconf.com/session-id/826051
[8] http://seblagarde.wordpress.com/2012/11/28/siggraph-2012-talk/

Nice write-up. Pretty much agree with everything. Regarding “The Bad” – while you usually can pretty safely fall back to blending out the reflections need the edges of the screen (bad no. 1) and when reflected vector starts facing camera (bad no. 2), it’s pretty difficult to deal with bad no. 3. In my experience, this is what generates the ugliest artifacts (including those shadow-like ghosts behind moving characters). I did some experiments with blurring the reflection mask near those edges, but never got any results that I would consider satisfactory.
Sometimes, even falling back to cubemaps is problematic. If they are placed sparsely (or even if the reflection-proxy box is just slightly off) screen-space reflection can be completely different than the one from the reflection probe – resulting in some weird mix of nice reflections and total garbage.
But it sometimes can work wonders (especially if the reflecting surface is flat with moderate glossiness 😉 – so, as usual, you just need some competent artists to get most out of it.
Out of curiosity – did you try tracing into lower-resolution/pre-blurred versions of the frame buffer to get reflection for lower glossiness levels? I did some really basic tests, the results were shitty, so I dropped it, but I’m curious if anyone had any more luck.
Thanks for your comment, it is very interesting. 🙂
Yes, I totally agree about the importance of problems coming from lack of enough screenspace information.
As for #1 we were actually “vignetting” the effect by default and for screen corners not even attempting to calculate it.
For #2 when vectors aggressively targeted the camera we did exactly the same, but problem with 3rd person perspective characters is often more subtle – sometimes reflected vector just runs almost parallel to the camera plane and sometimes it is possible to get some useful data (for example for opposite walls), but mirror like surfaces with no reflected characters or characters being reflected wrong is IMO quite a nightmare, especially for ADs. (unless you are making a vampire game 😛 )
For #3 I thought about having a dynamic, per material / object collision depth acceptance threshold (some engines already have material ID, it could easily help at least the ghosted character reflection case), but didn’t have opportunity to really use it.
With the rest of your comment I 100% agree and that localized cubemaps are not perfect solution (and what about dynamic ToD games? dynamic weather games? partially rebuilt / relit cubemaps?), it can be especially problematic for games with lots of both metallic and shiny surfaces, as even the tiniest artifact can become really visible in HDR.
I will talk a bit more about final used technique, but I did both pre blurring of source image (it was half res so to reduce aliasing / flickering artifacts – this part was gloss independent) and blurring / flood filling the final reflection texture. (separable wide blur with radius based on gloss and differently weighting samples based on “confidence”)
Pingback: My upcoming GDC 2014 presentation | Bart Wronski
Pingback: CSharpRenderer Framework update | Bart Wronski
Pingback: Local linear models and guided filtering – an alternative to bilateral filter | Bart Wronski